
Intel ha aprovechado la presentación del modelo de inteligencia artificial Llama 2, de Meta AI (la compañía de Facebook) para enseñar músculo con un extenso catálogo de productos perfectos para este y otros modelos de IA.
Intel enseña músculo con su catálogo de productos para modelos de lenguaje natural (LLM) como Meta Llama 2

Llama 2 tiene una gran relevancia puesto que es un modelo de código abierto, cualquier particular o empresa puede entrenarlo y usarlo en concordancia con sus necesidades, creando una especie de «ChatGPT adaptado». Hay muchas compañías que están incorporando chatbots mejorados con modelos de lenguaje similares, por ejemplo. Pues bien, Intel quiere mostrar todo el hardware que tiene para el entrenamiento e inferencia de este tipo de modelos.
Acelerador de Deep Learning Habana Gaudi2, perfecto para LLM como Llama 2

Primero hablemos de Habana Gaudi2, el acelerador de deep learning que cuenta con 96GB de memoria HBM2E y 24 puertos Ethernet Gigabit 100 para una escalabilidad inmensa. Esta es una bestia que supera el rendimiento en inteligencia artificial de tarjetas gráficas como la NVIDIA A100, y como decimos puede enlazarse de forma ultrarrápida con otras tarjetas.
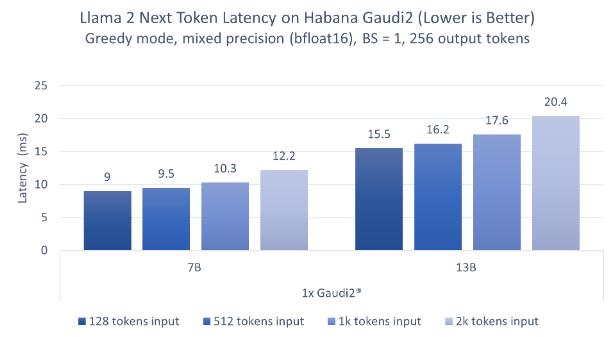
Con 1 sola tarjeta Gaudi2, alcanzan una latencia por token de entre 9 y 20 milisegundos por token en la inferencia del modelo Llama 2, es decir, que la generación de respuestas es ultrarrápida.
Procesadores Intel Xeon Scalable
Los procesadores Intel Xeon Scalable son de propósito general, pero cuentan con aceleradores específicos para IA gracias a las instrucciones Intel AMX, compatibles con las principales librerías de IA. En este caso, alcanzamos unas latencias de entre 42ms y 153ms con un único Xeon (comparan el 9480 y el 8480).
Intel Data Center GPU Max
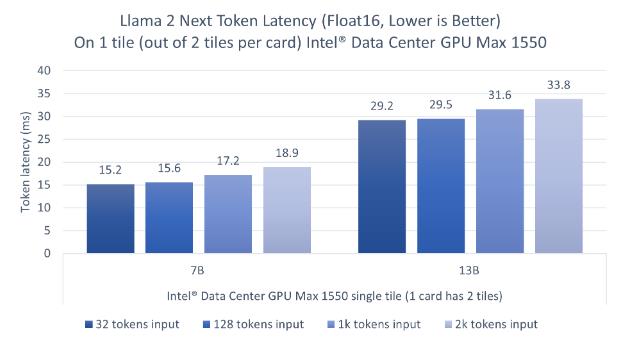
Finalizamos a este breve repaso de las capacidades de Intel con su Data Center GPU Max, una serie de tarjetas gráficas de máximo rendimiento destinadas a centros de datos. Estas consiguen un rendimiento excelente en IA gracias a sus 408 MB de caché L2, 64MB de caché L1 y hasta 128GB de memoria HBM2E, y las extensiones Intel XMX.
Aquí la tecnología de Intel Xe se lleva al máximo con unas latencias por token que pueden quedarse por debajo de los 20 milisegundos y con la posibilidad de trabajar con instancias paralelas.
Te recomendamos la lectura de los mejores procesadores del mercado.
Intel ha dado muchos más detalles al respecto, por lo que si eres un profesional de la industria interesado te recomendamos echarle un vistazo a la nota de prensa completa lanzada por la compañía.





