
Tanto si te interesa el tema de la arquitectura de una GPU, como si vas a elegir una nueva tarjeta gráfica para tu equipo, es importante conocer algo más sobre el chip de ésta, cómo usar los SKUs, y generaciones a tu favor, etc. Al igual que en el artículo tutorial sobre la microarquitectura de la CPU, en este otro nos centraremos en esta otra unidad que se puede usar para algo más que para los gráficos.
Índice de contenidos
CPU vs GPU: diferencias

No debes guiarte por su nombre para determinar para qué sirve cada una de ellas. En el pasado la CPU se encargaba también de los gráficos, cuando no existían aceleradores gráficos. Incluso actualmente, algunas CPUs se siguen encargando de los gráficos en algunos sistemas, como cuando se usa para el renderizado. Por otro lado, la GPU no solo puede procesar gráficos y nada más, ya que puede tener otras aplicaciones, como la GPGPU, que se puede usar como una CPU, con propósito genérico.
- CPU: son las siglas de Central Processing Unit, o unidad de procesamiento central. Las características más destacadas son:
- Destinada a procesamiento de propósito general.
- Suele tener una arquitectura homogénea, aunque algunas de las últimas CPUs también hayan incluido la heterogeneidad entre sus núcleos.
- Tiene unos pocos núcleos, desde algunas unidades a algunas decenas.
- Diseñada para baja latencia.
- Buena para procesamiento serial.
- Apta para diseñar unas pocas operaciones al mismo tiempo.
- Los núcleos son más rápidos e «inteligentes». Por ejemplo, pueden ejecutar instrucciones fuera de orden.
- Los núcleos son más flexibles que los de la GPU.
- GPU: son las siglas de Graphics Processing Unit, o unidad de procesamiento gráfico. En este caso, sus puntos llamativos son:
- Suele estar destinada para procesamiento gráfico, aunque puede hacer otras tareas.
- Tiene una arquitectura heterogénea, ya que sus unidades de procesamiento pueden ser de varios tipos.
- Tiene muchos núcleos. Pueden ser hasta cientos de ellos.
- Diseñada para alto rendimiento.
- Buena para procesamiento paralelo.
- Apta para realizar miles de operaciones al mismo tiempo.
- Los núcleos son menos rápidos e «inteligentes», son más pequeños y simples, pero más numerosos como he comentado.
- Los núcleos son menos flexibles que los de la CPU.
- La GPU también tiene ISA, como la CPU, pero ésta oculta al programador.
Por otro lado, me gustaría agregar que la CPU es el «cerebro» de la computadora, y que ello también implica enviar órdenes a la GPU. Por tanto, la GPU es dependiente de la CPU.
Arquitectura de la GPU
![]()
Existen varias compañías que diseñan GPUs, como Intel, AMD y NVIDIA para el ámbito del PC y el HPC, así como también han diseñado algunas para el sector de los dispositivos móviles, e incluso otras como Imagination Technologies (PowerVR Technologies) para ARM, Apple Silicon, Qualcomm (sus Adreno surgieron de una compra de la división móvil de ATI/AMD), etc.
Todos ellos tienen arquitecturas muy diferentes en cada GPU. Por este motivo, no se pueden comparar entre ellas a la ligera, ni tampoco los FLOPS se deben usar como unidad de referencia para comparativas. Y esto es debido a la heterogeneidad de unidades de procesamiento que existe, dando resultados muy diferentes.
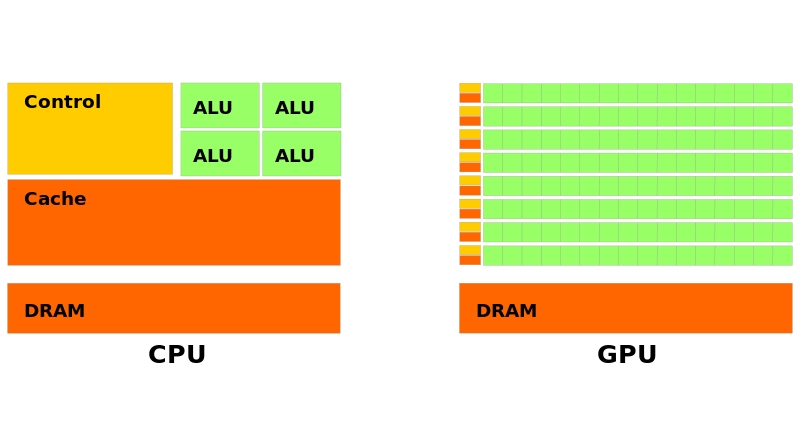
Las unidades computacionales o núcleos de una GPU son mucho más pequeñas y simples que las de una GPU, sin embargo, al ser tan numerosas, la potencia de cálculo es bastante impresionante, especialmente en coma flotante. De hecho, el núcleo de una GPU lo que más hace es sumar y multiplicar (MAD), y multiplicar-sumar (FMA). Otros núcleos algo más complicados, como las unidades tensionales o Tensor units, pueden hacer tareas algo más complejas que eso, como las operaciones tensor para acelerar IA (Inteligencia Artificial). Otros núcleos complejos son los de trazado de rayos, destinados a aportar mayor realismo en la iluminación.
El modelo de programación de los núcleos de la GPU es SIMD (Simple Instruction Multiple Data), es decir, con una instrucción única se aplica a varios datos, como una unidad vectorial. Dicho de otro modo, la GPU hará que un flujo de datos, que ocupará todos sus núcleos de procesamiento, sufra sea alterado al ejecutar una misma instrucción para todos. Así es como se consigue un alto paralelismo.
Estos modelos SIMD permiten acelerar una gran parte de aplicaciones, entre ellas las gráficas. En este caso para escalar todos los píxeles de una imagen, mapearlos, agregar texturas, iluminación, etc. Procesos que implican de una gran cantidad de datos matemáticos.
Evidentemente, estarás pensando que, al igual que un una CPU no se llenan todas las unidades funcionales, en una GPU tampoco vas a toparte siempre con un modelo que coincide especialmente con el SIMD, como cuando se procesan problemas asíncronos, por lo que va a producir una carga desigual en los núcleos de procesamiento en algunos casos.
Como se puede apreciar en la imagen anterior, la GPU se representa como un «mar» de unidades de procesamiento (marcadas en verde), y que pueden actuar de forma independiente. Por ejemplo, imagina sumar los elementos de una matriz de 8 filas. Para ello, se necesita obtener el primer elemento, sumarlo al segundo, el resultado sumarlo al tercer elemento, y así sucesivamente. Luego se hace lo mismo con la segunda fila, después la tercera,…
Este tipo de operaciones matriciales se pueden hacer de forma muy eficiente, rápida y simultáneamente con una GPU. Para ello se transforma este problema secuencial en algo paralelo. Para ello, se pueden sumar de dos en dos en paralelo los primeros parciales, logrando 4 resultados en este caso. Esos parciales se sumarán, y por último se suman los 2 últimos parciales. De esta forma, mientras una unidad de procesamiento convencional necesitaría muchos pasos, una GPU solo lo hace en 3.
Siguiendo con este ejemplo, la GPU lo que hará será emplear cuatro unidades de procesamiento en el primer ciclo de reloj para la suma y obtención de los cuatro parciales. Luego, en la siguiente oscilación de reloj se usarán dos núcleos para la suma de los cuatro parciales, y por último un núcleo para la suma de estos dos últimos. Así es como la GPU trabaja a nivel de arquitectura.
Como habrás deducido, de esto se puede ver que la GPU necesitará un espacio de memoria compartida para almacenar y obtener los resultados parciales. Cada unidad de procesamiento o núcleo se organiza en Streaming Processors, o procesadores de flujo, cuyas unidades de procesamiento dentro del grupo pueden ser de varios tipos. Estos grupos puede colaborar entre sí de forma mucho más sencilla que si se relacionaran todos con todos como sucede en una CPU.
AMD usa Compute Units o CU para designar a las unidades de procesamiento, y NVIDIA los llama SM o Streaming Multiprocessor. Cada una de estas unidades está integrada por un conjunto de subunidades, como los motores de sombreado, unidad de textura, unidad de rasterizado etc.
Estos elementos de procesamiento pueden realizar diversas operaciones, como: FP32 o de coma flotante de precisión simple; FP64 o de coma flotante de doble precisión; enteros para datos enteros, por ejemplo para cálculos de direcciones, etc.; tensoriales o Tensor Cores son agrupaciones de coma flotante tipo FP16 o de precisión media. Esas operaciones algo más simples son las más comunes en el aprendizaje profundo o IA. En las modernas arquitecturas de GPU se pueden integrar varios tipos de elementos, como por ejemplo:
- Motores de sombreado: también conocidos como shaders, encargados de la transformación de la geometría, tanto a nivel de color como de sombreado. Por ejemplo, efectos de iluminación, reflejos, neblina, etc.
- Unidades de rasterizado: los ROPs se encargan de representar la imagen a partir de vectores. Así obtienen el conjunto de píxeles que la componen y se escribe el resultado en el framebuffer, desde allí son transmitidos a la pantalla. También podrían aplicar filtros o suavizados (el famoso antialiasing).
- Unidades de texturizado: suelen conocerse como TMUs, y se ocupan, como su propio nombre indica, de mapear las texturas en la geometría. Es decir, adornan la forma generada con la textura. Por ejemplo, imagina que se ha creado una esfera en 3D, y esa esfera es un balón de fútbol en un videojuego, pues esta unidad hará que esa esfera tenga el aspecto de un balón.
- Motor RT: suelen usarse para acelerar el trazado de rayos y mejorar la calidad de imagen. No están en todas las GPUs, solo en las últimas generaciones.
- Núcleo Tensor: para acelerar la IA, y también son núcleos bastante nuevos. Se centran en la inferencia, IA y aprendizaje profundo, para mejorar la imagen mediante tecnologías como FSR de AMD, DLSS de NVIDIA, etc.
- Otras.
Dependiendo de la arquitectura de GPU, esas unidades pueden variar. Y, por supuesto, no hay que olvidar el bus de memoria de la GPU para comunicarse con ella con un ancho de banda elevado, y de la memoria gráfica o VRAM. Ésta juega un papel fundamental en el proceso, ya que guardará elementos y datos de los gráficos ya procesados, y en función de la resolución, se necesitará más cantidad de esta memoria o menos. Así se puede recurrir a ellos cuando se necesite, sin volver a procesarlos. En caso de tener menos memoria y que no quepan todos, se deberá volver a procesar todo, lo que supone un impacto en el rendimiento.
En la imagen superior puedes ver estos Streaming Processors en forma de líneas de unidades de procesamiento en verde, con partes a la izquierda de memoria compartida y control del flujo. Esta memoria no es la VRAM, o RAM para gráficos, sino que es una memoria tipo caché built-in en la GPU, mientras la VRAM es externa (en las iGPU o APUs, la memoria empleada por la GPU es la RAM principal, que compartirán con la CPU).
Cómo trabaja una GPU

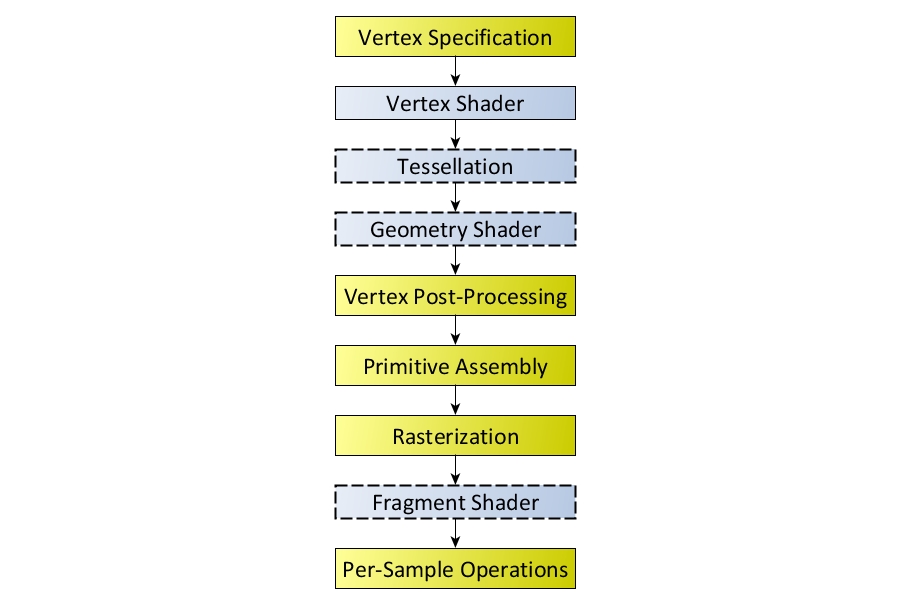
Tras explicar de forma sencilla cómo es la arquitectura de una GPU, vamos a ver cómo trabaja esta para generar los gráficos. Es decir, cómo esas operaciones matemáticas se transforman en un gráfico 2D o 3D en nuestra pantalla. Haciendo un resumen simplificado, la tubería gráfica se compone de los siguientes pasos:
- La GPU calcula unos puntos que se usarán para los vectores. Este modelo compondrá triángulos y un grupo de triángulos formará a su vez polígonos y formas. Estos pueden ser trasladados, o rotados.
- Luego, la geometría de la escena creada se iluminará ubicando las distintas fuentes de luz que pueda haber. Además también representará los reflejos y otras propiedades superficiales.
- Ahora llegaría la transformación de la vista, transformando coordenadas para la escena 3D con la posición y orientación que se necesita.
- El proceso denominado clipping eliminará esas primitivas geométricas que quedan fuera de la visión o frustum. Ten en cuenta que, la GPU representa una forma completa, pero no toda ella se verá en la pantalla. Dicho de otro modo, imagina que estás frente a una taza, y que con el sensor de la cámara de tu móvil apuntas a esa taza. En la pantalla vas a ver solo un lado de la taza, ese será el que se obtenga durante el clipping.
- Después llega el momento del shading o texturizado, que simplemente aplicará texturas y color a la escena.
- Le sigue la rasterización, que es el proceso por el cual se representa la escena en el espacio de la escena 2D o 3D.
- Por último se realiza la visualización, cuando los datos procesados se muestran en pantalla. También puede que esa imagen generada se emplee para otro fin, dentro de otra tubería de renderizado. Por ejemplo, imagina que esa taza se represente en una habitación sobre una mesa… entonces se volverán a recrear el resto de elementos.
Por supuesto, la GPU no trabaja sola. La CPU es la que le encargará las tareas, mediante el envío de comandos y datos, durante el procesamiento del videojuego o del software gráfico que sea. Y a eso hay que agregar APIs gráficas como OpenGL, Vulkan, etc., los controladores gráficos que trabajarán a nivel bajo con la GPU, etc.
- Los drivers o controladores de la GPU trabajan a bajo nivel, entre la GPU y el software de aplicación que usa ésta. También es responsable de convertir, con ayuda de la CPU, cualquier otro tipo de dato para que sea comprensible para la GPU. Y, por supuesto, también proporcionará una interfaz abstracta a los programas gráficos.
- Entre el controlador y la API tenemos también otro tipo de controlador dependiente del anterior. Se encarga de traducir llamadas de OpenGL a llamadas a las funciones específicas que tiene el controlador de la GPU para que pueda controlarla.
- También tenemos la API gráfica, como puede ser OpenGL, DirectX 3D, Vulkan, etc. Este framework o biblioteca provee a los programadores de una serie de funciones para generar los gráficos.
Te recomendamos la lectura de los siguientes tutoriales:
Con esto terminamos nuestro artículo sobre la arquitectura de GPU. Esperemos que os haya servido de utilidad, y si tienes alguna duda, estamos a vuestra disposición. ¡Hasta el próximo artículo!






