
Los núcleos tipo performance-core y efficient-core pueden ser una buena solución para aportar rendimiento y eficiencia a las nuevas microarquitecturas, aunque no todo son ventajas en este tipo de arquitecturas de núcleos heterogéneos. Además, esto no solo implica al lado del hardware, también es imprescindible que el kernel del sistema operativo sepa cómo gestionar este tipo de núcleos para sacar el máximo provecho de ellos.
Aquí tienes todas las claves sobre este tipo de núcleos heterogéneos que se están apreciando en diseños como el Intel Alder Lake, o en muchos otros Arm Cortex para dispositivos móviles, así como su funcionamiento.
Índice de contenidos
Topología heterogénea de la CPU

Las CPUs x86-64, desde que se han implementado como multinúcleo, han venido siendo homogéneas. Sin embargo, en las GPUs o en los procesadores destinados para dispositivos móviles, como los Arm, sí que se lleva años empleando una topología de núcleos heterogéneos. Con la misma ISA, pero con diferencias notables en la microarquitectura, velocidad, etc. El setup de estos sistemas es similar al multiprocesador simétrico, aunque con algunas diferencias, como los roles de cada tipo de núcleo.
En las CPUs con núcleos heterogéneos suele haber 2 tipos de núcleos: los de alto rendimiento o P-cores (performance-core) y los eficientes energéticamente o E-core (efficient-core). Los primeros son de mayor tamaño por su complejidad, y mayor consumo, pero son capaces de rendir más. Los segundos son más simples, pequeños, y consumen menos, pero también rinden menos.
Algunas implementaciones conocidas de este tipo de arquitectura heterogénea son:
- Arm big.LITTLE (sucedida por DynamIQ): esta fue una de las pioneras en hacer esto en el ámbito de la CPU. Arm, para mejorar la eficiencia en sus procesadores para dispositivos móviles, implementó núcleos de alto rendimiento combinados con núcleos de bajo consumo (en algunos diseños también existen unos núcleos intermedios, por lo que son tres tipos en vez de dos). Se agrupan en clusters, de tal manera que cuando se ejecuta una app que no demanda demasiados recursos, o una carga ligera, se emplean los efficient-cores (aquí denominados LITTLE), consumiendo menos energía y alargando la autonomía de los dispositivos con batería. Por otro lado, cuando la carga de trabajo es alta o se necesita mayor rendimiento, se activan los performance-core (denominados big), que consumen más, pero que podrán soportar esa carga. Android (kernel Linux) funciona a las mil maravillas con este sistema.
- Appel Silicon: para los chips diseñados por Apple también se pueden apreciar organizaciones de núcleos similares. Estos núcleos también se basan en la ISA ARMv8. Por ejemplo, en un A14 Bionic se pueden encontrar agrupaciones de núcleos tipo performance-core como los Firestorm, y efficient-core como los Icestorm. En este caso, iOS/iPadOS está optimizado para funcionar a la perfección con estas configuraciones. Lo mismo ocurre en el M1 y macOS.
- Intel Lakefield/Alder Lake: la compañía de Santa Clara ha sido la primera en llevar este paradigma de núcleos heterogéneos al mundo x86, con una combinación de núcleos tipo performance-core con los que consigue mayor rendimiento, y los efficient-core en los que sacrifica rendimiento a costa de ganar en eficiencia energética. El SO Microsoft Windows se ha adaptado bien a este cambio, otros no tanto.
DynamIQ aportará mayor flexibilidad y escalabilidad que big.LITTLE. Por un lado se incrementan los núcleos máximos por cluster a 8, y hasta 32 clusters. Además, es importante destacar que también admite variedad de núcleos dentro de un mismo cluster. También está pensado para acelerar la L2 y tener un control más fino del voltaje de los núcleos. Los primeros en soportar esta tecnología son los Cortex-A55 y Cortex-A75.
El concepto es bastante bueno, sin embargo, para hacerlo funcionar de forma eficiente se necesita que el sistema operativo sea capaz de gestionar todos estos grupos de forma adecuada. Para ello, el kernel debe tener un planificador capaz de reconocer las cargas o procesos y determinar qué núcleos deben encargarse de ello, empleando los diferentes funciones que provee ACPI. Y lo cierto es que esto no es tan sencillo como puede parecer. Algunos sistemas operativos están teniendo problemas con ello.
Performance-core vs Efficient-core

En esta imagen, que no es más que un dieshot del Intel Alder Lake, se puede apreciar varias cosas interesantes. Por un lado he marcado con dos rectángulos negros los núcleos tipo performance-core de esta microarquitectura. Cuatro arriba y cuatro abajo, separados por la caché. También he marcado en un tono amarillento el espacio ocupado por un solo núcleo de alto rendimiento.
A la derecha, justo al lado de la zona de la GPU se pueden apreciar muy bien los otros 8 núcleos tipo efficient-core que he rodeado con un recuadro azul. Nuevamente cuatro arriba y cuatro abajo, separados por la zona de caché. En amarillo también está marcado el espacio ocupado por uno de estos E-core, que comparado con un P-core, se aprecia que es bastante más pequeño.
Ahora bien, hecha esta comparación visual, vamos a ver algo más sobre qué son estos núcleos empleando dos ejemplos:
El caso Arm big.LITTLE para Cortex-A53 y Cortex-A72
En el caso de big.LITTLE de Arm, a pesar de cambiar la microarquitectura de los núcleos y la frecuencia de reloj, lo que no cambia aquí es las instrucciones que puede manejar cada uno, que son las mismas (ARMv8-A para este ejemplo).
- big: lo que se usa es un cluster con un tipo de Arm Cortex-A de rendimiento superior, acompañado por otro cluster de Cortex-A de rendimiento algo inferior y más eficiente. En algunos casos incluso puede haber un cluster intermedio. Por ejemplo, en un SoC Mediatek Helio X20 encontramos los Cortex-A72 trabajando a una frecuencia de 2.5 Ghz y aportando mayor rendimiento para cargas pesadas. Esta implementación de la ISA ARMv8-A de 64-bit tiene un decodificador de tres vías, con ejecución fuera de orden y una pipeline superescalar. En cuanto a la memoria caché, cada núcleo tiene una L1 de 80 KiB para instrucciones y 32 KiBpara datos con ECC. La L2 representa el LLC, y es compartida y unificada, de 512 KiB hasta 4 MiB.
- LITTLE: siguiendo con el mismo ejemplo, también hay un grupo de Cortex-A53 ULP a 1.4 Ghz, siendo los eficientes, para cargas ligeras y ahorrar batería. Y se agrega un cluster intermedio de Cortex-A53 a 2Ghz en este caso, para cargas de trabajo intermedias. Se pueden incluir de 1 a 4 núcleos por cluster, aunque permite usar varios clusters. Las especificaciones de este otro núcleo, básicamente es una implementación de la ISA ARMv8-A de 64-bit, con dos vías de decodificación, superescalar, con ejecución fuera de orden, memoria caché L1 de entre 8 y 64 KiB, L2 de 128 KiB a 2 MiB, y solo admite un único cluster con entre 1 y 4 núcleos.
A nivel de software, no se pueden usar todos los clusters de forma simultánea, actualmente sí que se permite. Según la carga de trabajo, el scheduler del kernel podrá elegir usar uno, varios o todos los núcleos. Además, se mejora aún más la eficiencia combinando esto con otras prácticas como escalado dinámico de voltaje y escalado dinámico de frecuencia (throttling), es decir, a través de los gobernadores del kernel se pueden seleccionar varios estados según las necesidades en cada momento o de la temperatura.
El caso del Intel Alder Lake
Intel Alder Lake ha optado por una solución algo diferente para sus unidades heterogéneas. Por un lado tiene los núcleos tipo performance-core o P-core, que soportan la ISA completa y todas las extensiones. Y por otro lado tenemos los núcleos E-core que no soportan todas las extensiones. Es decir, los P-core son EM64T + AVX-512 (entre otras extensiones) y los E-core son EM64T sin soporte para AVX-512.
Según para qué vaya destinado Alder Lake, puede tener varios tipos de configuración en sus módulos. Por ejemplo, para el escritorio se emplean 8 P-cores + 8 E-cores. Mientras que para portátiles se 6 P-cores + 8 E-cores. Y para equipos ultrabooks 2 P-cores y 6 E-cores.
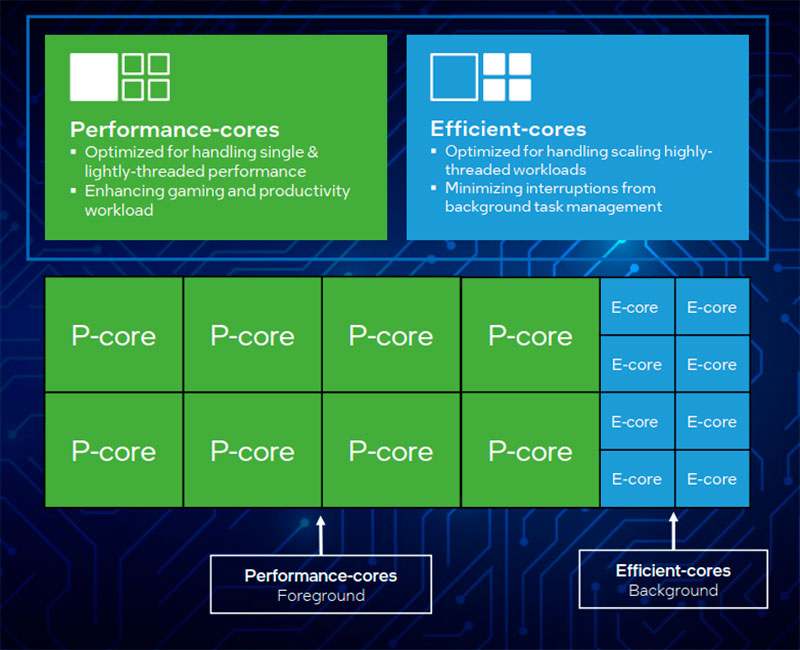
- P-core: son unidades Golden Cove (una mejora de Skylake usada en los Intel Core de 6ªGen), una microarquitectura para los núcleos tipo performance-core que puede trabajar a frecuencias entre 1 Ghz y 5.5 Ghz, con caché L1 de 80 KB por núcleo (32 para instrucciones y 48 para datos), L2 de 1.25 MB (cliente) o 2MB (servidor), así como una caché L3 de 3MB por núcleo. Soporta la ISA EM64T de 64-bit, y las extensiones AES-NI, CLMUL, RDRAND, SHA, TXT, MMX, SSE, SSE2, SSE3, SSSE3, SSE4, SSE4.1, SSE4.2, AVX, AVX2, FMA3, AVX-512, AVX-VNNI, TSX, VT-x, y VT-d. La FPU y registros necesarios para AVX-512 hacen que estos núcleos sean más grandes y consuman más.
- E-core: estas unidades Gracemont son una microarquitectura basada en Tremont (Intel Atom de 4ªGen) que ha sido mejorada. Emplea ejecución fuera de orden, tiene bajo consumo, y puede trabajar a frecuencias entre 700 Mhz y 4 Ghz. En cuanto a la memoria caché, tiene L1 de 96 KB (64 KB para instrucciones + 32 KB de datos) por núcleo, L2 de 2 o 4 MB por módulo, L3 de 3 MB por módulo. El módulo es lo que Arm llama cluster, es decir, un conjunto de núcleos Gracemont de entre 1 y 4 unidades. Se trata de una ISA EM64T de 64-bit, pero en este caso las extensiones soportadas se limitan a MMX, SSE, SSE2, SSE3, SSSE3, SSE4, SSE4.1, SSE4.2, AVX, AVX2, FMA3, AVX-VNNI, AES-NI, CLMUL, RDRAND, SHA, TXT, VT-d, VT-x. Al carecer de AVX-512, se simplifica mucho el núcleo, haciendo que sea más pequeño y consuma menos.
AMD también parece apuntar a este tipo de arquitectura, pero llegará con Zen 5 (Ryzen 8000 Series), donde se emplearán núcleos tipo performance-core basados en Zen 5 y núcleos tipo efficient-core basados en Zen 4D (también denominado Zen 4 Dense).
En el sistema operativo Windows 10 y 11, Alder Lake cuenta con un buen soporte. El kernel Windows NT hace bien su trabajo, aunque en Windows 11 se ha mejorado respecto a la anterior versión del sistema operativo de Microsoft. Windows 10 se centra más en el poder de los núcleos, mientras que Windows 11 también se centra en la eficiencia. El planificador de Windows 11 sabe incluso cómo se va a comportar cada núcleo a una frecuencia determinada para una carga de trabajo establecida, así puede asignarlo al que mejor lo haga.

Todo eso es gracias al Thread Director implementado en el kernel Windows NT para Windows 11, un algoritmo capaz de identificar el IPC efectivo de un flujo de trabajo y aplicará métricas de rendimiento/eficiencia, moviendo el hilo hacia donde sea mejor. Para esto el algoritmo usa cuatro clases de cargas de trabajo:
- Clase 0: son la mayoría de los programas o aplicaciones. Como navegadores web, programas de ofimática, editores de texto, clientes de correo, etc.
- Clase 1: cargas de trabajo que emplean instrucciones AVX/AVX2, algo más pesadas. Por ejemplo, programas multimedia y de codificación como Adobe After Effects, Premiere, Excel, MATLAB, Octave, des/compresores como PeaZip, 7 Zip, WinRAR, etc., así como programas que emplean codificación de vídeo o sonido…
- Clase 2: cargas de trabajo que usan instrucciones AVX-VNNI, como algunas aplicaciones de redes neuronales.
- Clase 3: otras cargas pesadas que pueden generar cuellos de botella, como E/S, ciertos bucles, etc.
Para cualquier cosa de Clase 3 se empleará preferentemente E-cores, mientras que Clase 0, 1 y 2 es para P-cores. Sin embargo, el sistema operativo no es rígido en este sentido, y podría forzar cualquier tipo de carga de trabajo a cualquier núcleo tipo performance-core o efficient-core según las necesidades del usuario.
Ventajas y desventajas

Como suele ocurrir con todos las tecnologías, tiene sus ventajas y desventajas:
- Ventajas:
- Mejora la eficiencia energética, bajando el consumo y haciendo que los dispositivos que dependen de la batería tengan mayor autonomía.
- Admite incluir núcleos heterogéneos que se encarguen de tareas diferentes.
- No necesita alterar el código fuente de los programas. Es decir, a nivel de usuario, el código del software no debe ser alterado para soportar este tipo de arquitecturas. Es el planificador del kernel el que se encarga de ello. Las aplicaciones se ejecutan como procesos y el planificador determinará cuándo y cómo se procesan.
- Desventajas:
- Mayor complejidad del lado del kernel del sistema operativo.
- Mayor complejidad del lado del hardware, para implementar varios tipos de núcleos trabajando juntos.
- Interferencias a la hora de hacer overclocking en los P-cores, limitados por los E-cores.
- ¿Menor eficiencia? Aunque pueda parecer contradictorio, en el caso de la implementación tipo Intel, si un programa, aunque no sea demasiado pesado, usase el set de instrucciones AVX-512, estaría despertando a un núcleo de alto rendimiento sin otra alternativa, ya que los núcleos pequeños no lo soportan… Y no solo eso, sino que a la hora de realizar cambios de contexto puede ser más lento.
Te recomendamos la lectura de los mejores procesadores.
Con esto terminamos nuestro artículo sobre Performance-core y Efficient-core. ¿Os parece más interesante estos procesador de alta gama con esta tecnología o preferís los clásicos i3 e i5 que tan buen rendimiento están dando?






