Instalar IA local en Linux implica configurar entornos, dependencias, aceleración por GPU y modelos optimizados. Es un proceso cada vez más accesible gracias a herramientas modernas, pero que aún sigue generando algunas dudas para muchos usuarios. Además, a diferencia de Microsoft Windows, no viene con un Copilot por defecto, sino que hay que usar proyectos de terceros para tener algo similar, o para trabajar de forma local con la IA.
Índice de contenidos
Si te interesa este sistema, puedes leer más sobre Linux aquí
Es importante tener instalados los drivers y dependencias necesarias si vas a usar la GPU. Puedes mirar nuestros tutoriales de CUDA y ROCm.
Ollama
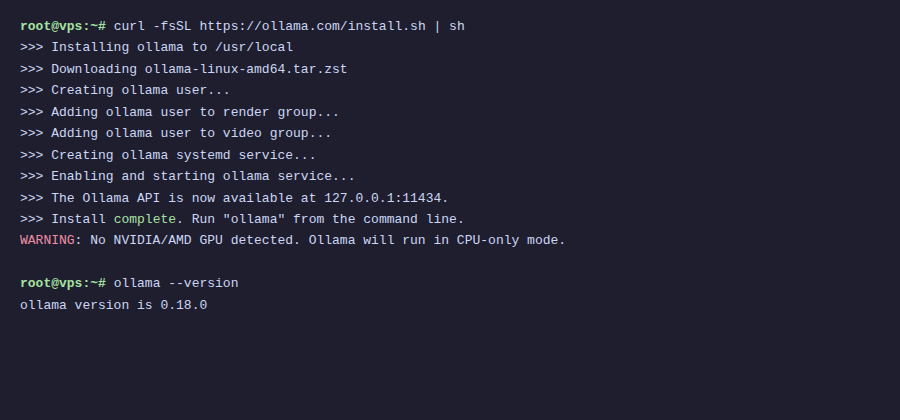
Ollama es un runtime diseñado para ejecutar modelos LLM en local con extrema facilidad. Permite descargar, gestionar y ejecutar modelos con un solo comando. Está optimizado para CPU y GPU (NVIDIA/AMD) y usa el formato GGUF. Este software es muy sencillo de usar, permite integración con APIs locales, gestión automática de modelos que puedes descargar y usar.
Instalación de Ollama en Linux
Para la instalación de Ollama en Linux, basta con abrir el terminal y ejecutar el comando:
curl -fsSL https://ollama.com/install.sh | sh
Eso hace que se descargue y se ejecute el script de instalación. Ahora, reinicia el servicio con:
systemctl --user start ollama
Por último, puedes verificar que se ha instalado bien con el comando:
ollama --version
LM Studio
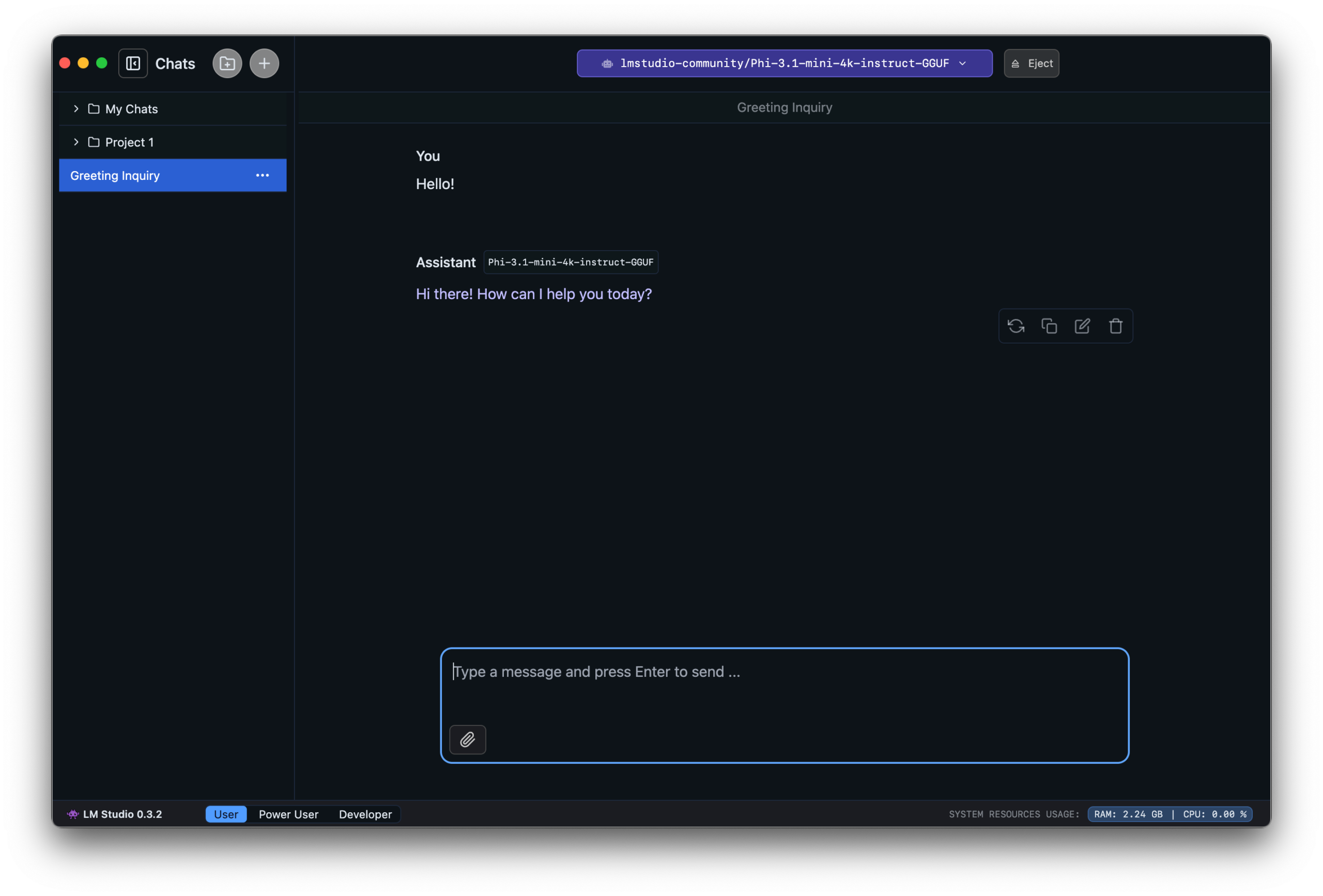
LM Studio es una aplicación de escritorio que permite descargar, probar y ejecutar modelos LLM localmente con una interfaz gráfica. Si no te gusta usar comandos, entonces puedes utilizar esta otra app. Además, incluye algunas facilidades, como un chat integrado para preguntar, opción para descargar modelos desde Hugging Face, motor de inferencia basado en llama.cpp y una API local compatible con OpenAI.
Instalación en Linux
- Ve a la página oficial y descarga el .AppImage.
- Dale permisos de ejecución:
chmod +x LM-Studio*.AppImage
- Ejecuta el archivo:
./LM-Studio*.AppImage
También hay paquete .deb si lo prefieres…
GPT4All
También se basa en una GUI para no tener que trabajar con comandos. GPT4All es un ecosistema completo para ejecutar modelos LLM en local, con soporte para bibliotecas Python, C++ y Node.js, descarga automática y gestión de modelos, y soporte tanto para ejecutar la carga en CPU y GPU.
Instalación en Linux
sudo dpkg -i gpt4all.deb sudo apt --fix-broken install
- Para .AppImage:
chmod +x gpt4all.AppImage ./gpt4all.AppImage
Jan
Jan es una aplicación de escritorio enfocada en privacidad y simplicidad. Todo se ejecuta en local, sin telemetría ni conexión externa. Al igual que las dos anteriores, también se basa en un entorno gráfico, por lo que no tendrás que usar comandos para el uso diario. También incluye chat para usar multitud de modelos, descargar modelos desde Hugging Face, una API local, y no necesita conexión una vez descargado el modelo.
Instalación en Linux
- Descarga el .AppImage desde la web oficial.
- Dale permisos:
chmod +x Jan*.AppImage
- Ejecuta:
./Jan*.AppImage
Como ves, cada vez existen más posibilidades para usar modelos de IA en local. Es importante que leas también nuestra guía para elegir y conocer los mejores modelos LLM de código abierto para descargar y usar según tus necesidades y los requisitos de hardware, ya que desde las funciones de descarga de modelos de estas apps te permite descargar numerosos y con tamaños diferentes.
Instalar IA (no local) como apps en Linux
El famoso ChatGPT de OpenAI también puedes usarlo en Linux. Existen tanto proyectos no oficiales basados en Electron para tenerlo como una app nativa, aunque se sigue usando el servicio online a través de ella (no es de forma local, por tanto), como también un paquete oficial de esta compañía. Si quieres instalar el oficial, los pasos son:
flatpak install flathub io.github.lawstorant.chatgpt flatpak run io.github.lawstorant.chatgpt
Si lo que quieres es tener Gemini de Google, entonces también es posible con este «truco» que nuevamente te permite usarlo como una app nativa, pero que tampoco se ejecuta en local:
- Abre tu navegador basado en Chromium (como Google Chrome, Chromium, Brave o Microsoft Edge).
- Entra en el sitio oficial: gemini.google.com e inicia sesión con tu cuenta.
- Ahora ve en el navegador a la barra de direcciones y en la derecha debe haber un icono de una pantalla con una flecha hacia abajo que dice «Instalar Gemini». Si no es así, puedes ir al menú (los tres puntos) del navegador web > Guardar y compartir > Instalar página como aplicación > Instalar.
El tercer gran conocido dentro de la IA es Copilot de Microsoft, que aunque no se pueda integrar en el sistema operativo de la misma forma que se hace en Windows 11, lo puedes usar también como app local, aunque recuerda que se ejecuta en remoto como los dos casos anteriores:
sudo snap install copilot-desktop
Si quieres tener algo parecido a Copilot en Windows 11, pero en tu distro Linux, lo que buscas es OpenClaw, una IA que tiene un control total sobre muchas funciones en tu sistema y que podrás gestionar desde el dispositivo móvil para controlar lo que necesites. Sin embargo, debes hacerlo con cuidado dada su alta capacidad. Para instalarlo solo tienes que hacer esto:
curl -fsSL https://openclaw.ai/install.sh | bash
Métodos avanzados
Existen otros métodos avanzados que pueden ser interesantes más allá de usar estos programas para modelos de IA. Por ejemplo, es posible que te interese utilizar WebUI en lugar de apps locales, como Text Generation WebUI o Stable Diffusion WebUI. Para esto, los pasos a seguir son:
- Text Generation WebUI: es una interfaz gráfica basada en web y capaz de ejecutar modelos de lenguaje localmente. Para su instalación:
git clone https://github.com/oobabooga/text-generation-webui cd text-generation-webui python -m venv venv source venv/bin/activate pip install -r requirements.txt pip install huggingface-hub #Ahora puedes descargar el modelo GGUF que quieras, por ejemplo, Llama: huggingface-cli download bartowski/Meta-Llama-3-8B-Instruct-GGUF --local-dir ./models/ #Y ejecutar la interfaz web python server.py *Nota: para acceder a la interfaz web, ve a tu navegador web y usa http://localhost:7860
- Stable Diffusion WebUI: en este caso, con una WebUI similar, pero para trabajar con Stable Diffusion, los pasos para su instalación serían:
sudo apt update && sudo apt install -y git python3 python3-venv python3-dev git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git cd stable-diffusion-webui #Ahora puedes lanzar la interfaz ./webui.sh #Cuando descargues los modelos .safetensors, tienes que ubicarlos en la ruta ~/stable-diffusion-webui/models/Stable-diffusion/
También es posible que estés interesado en ejecutar modelos de visión artificial en Linux, y esto lo puedes hacer con proyectos como YOLO y CLIP, y así poder trabajar con imágenes. En este caso, los pasos son:
- Instalar YOLO para poder detectar objetos en imágenes, vídeo y también desde una cámara en tiempo real:
python3 -m venv yolo_env source yolo_env/bin/activate pip install ultralytics #Para reconocer objetos, puedes usar comandos como: yolo predict model=yolo11n.pt source=nombre-de-la-imagen.jpg yolo predict model=yolo11n.pt source=nombre-video.mp4 yolo predict model=yolo11n.pt source=0
También se pueden hacer scripts en Python para detectar objetos usando Yolo. No solo con comandos directamente.
- Para instalar y trabajar con CLIP, para comprensión imagen-texto, debes ejecutar lo siguiente:
python -m venv clip_env source clip_env/bin/activate pip install torch torchvision transformers ftfy regex *Nota: ahora ya puedes usarlo en un script de Python, puedes ver ejemplos aquí
No olvides dejar dudas y comentarios…