
A primera vista, juntar varios Mac Mini parece un experimento de laboratorio, pero en realidad se ha convertido en una solución sorprendentemente práctica para quienes buscan potencia distribuida sin montar un servidor ruidoso y gigantesco. En este artículo exploramos por qué estos pequeños cubos de aluminio se han ganado un hueco inesperado en el mundo de la IA local.
Índice de contenidos
Arquitectura distribuida con macOS
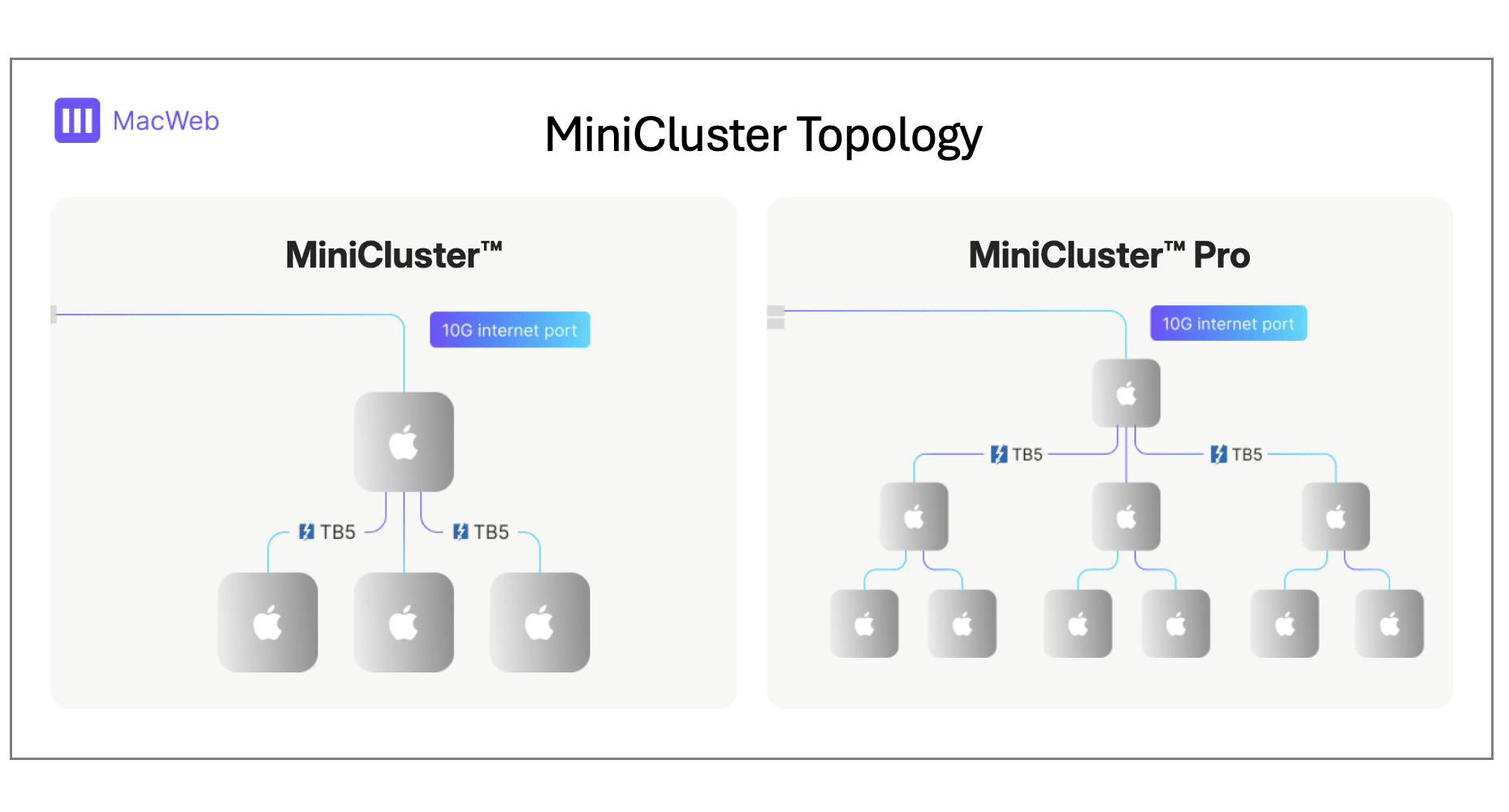
Antes de nada, me gustaría dejar algo claro, para no llevarnos a confusión. En macOS no se puede crear un cluster nativo como sí se puede hacer en Linux mediante proyectos como MPI, Slurm, etc., o como sí que se permitía antes con Xgrid en Mac OS X Server. Como sabrás, la versión server ha desaparecido, y lo que ocurre en este tipo de redes cuando conectas varios Mac Mini con macOS es que cada uno actua como un nodo de computación, usando protocolos y frameworks estándar de computación distribuida. Es decir, el sistema operativo no fusiona toda la RAM, CPUs, y GPUs de todos los Mac Minis, simplemente permite crear canales de comunicación de baja latencia para repartir una tarea entre los nodos disponibles para que se ejecute más rápidamente.
¿Y cómo funciona esta arquitectura? Pues bien, para comprenderlo, voy a ir paso a paso:
- Conexión en red de los Mac Mini mediante Thunderbolt Bridge, ya sea usando Thunderbolt 4 (hasta 40 Gb/s) o el nuevo Thunderbolt 5 (hasta 80 Gb/s bidireccionales), dependiendo del modelo. De esta forma, se puede transferir datos de forma rápida entre ellos, convirtiendo el cable Thunderbolt en un enlace IP punto a punto en esta red. Al conectar así, cada Mac se configura automáticamente, obteniendo una IP y comportándose como si fuese una red Ethernet.
- Como he dicho, macOS no incluye un sistema de clustering nativo, sino que se basa en una capa de comunicación entre procesos para permitir que los nodos «hablen» entre sí. Esta comunicación se realiza mediante ejecución remota y a través del protocolo SSH. De este modo, se pueden lanzar scripts distribuidos, colas o cargas. Se empleará Bonjour/mDNS para conocer otros nodos de la red, y se puede usar File Sharing/NFS/SMB para compartir datos, e incluso un NAS o SSD Thunderbolt externo para compartir un almacenamiento común.
- Aquí es donde entra en juego MLX Distributed Framework de Apple, que permite paralelizar cargas de IA en los Apple Silicon. Con Exo tenemos soporte para tensor parallelism, sharding, y monitorización, y RDMA sobre Thunderbolt 5 a partir de la versión macOS 26.2, Ray para tareas distribuidas con Python como worker, y MPI (OpenMPI) como Unix que es para computación científica tradicional. Pero hay que tener presente que macOS no interviene en la lógica de distribución de la carga de trabajo, solo proporciona una plataforma para los procesos.
- Cada macOS instalado en cada nodo, o cada Mac Mini en este caso, se encarga de planificar los procesos de forma local, sin compartir memoria, y recursos de cómputo con otros nodos como podría suceder en Linux. No existe una arquitectura NUMA en este caso, sino que cada Mini usa su propia memoria unificada sin conocer las del resto.
Dicho esto, podrás intuir que este tipo de cluster tiene sus limitaciones, como las que ya he dicho de incapacidad para fusionar los recursos de hardware como si fuesen solo una máquina o supercomputador, carece de un scheduler central tipo Slurm, y todo depende de software externo.
Te recomiendo leer nuestra review y análisis del ecosistema Apple para entornos profesionales.

Última actualización el 2026-06-27
Ventajas del hardware Apple Silicon en cluster

Aunque no funciona como un cluster convencional, usar el hardware Apple Silicon con esta configuración en red, tiene sus ventajas por las propias características de los SoCs Apple Silicon de la M-Series. Tengo que destacar:
- Escalabilidad: puedes unir varios Mac Mini, ampliando la capacidad de usar solo un Mac Mini con un SoC con capacidades fijas, y una memoria unificada limitada. De esta forma, se pueden usar modelos de IA más grandes de los que se podría usar en un solo equipo.
- Baja latencia: gracias al Thunderbolt Bridge, sin necesidad de usar cableado Ethernet y tarjetas de red de este tipo, se puede conseguir una red de conexión entre nodos de muy baja latencia. De hecho, supera en este sentido al Ethernet 10GbE y con mayor ancho de banda para mejorar el rendimiento tensor paralelo y la pipeline de ejecución paralela. Y todo esto es vital para ejecutar IA en local.
- Sharding: aunque la memoria unificada de cada nodo o Mac Mini no se comparte entre el resto de equipos, los frameworks modernos como Exo, Ray, y MLX Distributed se permite el sharding del modelo de IA, así como paralelismo tensor y pipeline, pudiendo cargar modelos que no cabrían en un solo Mac Mini, repartiendo partes del modelo entre Mac Minis.
- Eficiencia energética: gracias a que Apple usa un sistema operativo muy optimizado para el hardware, y que los chips Apple Silicon tienen una gran eficiencia gracias a su base ARM, permite tener un equipo de alto rendimiento con un consumo más bajo incluso que otros servidores x86 o con GPUs dedicadas. Esto puede ser muy bueno para entrenar modelos o para habilitar modelos que funcionen 24/7, con el mínimo consumo eléctrico. Además, al generar poco calor, no necesitas un sistema de refrigeración ruidoso y aparatoso como con otros clusters.
- Administración sencilla: como sabes, Apple destaca por que su software es extremadamente intuitivo y fácil de usar. Y esto también se aprecia aquí, donde la puesta en marcha y el mantenimiento es extremadamente sencillo. Y si un nodo falla, porque deja de funcionar, simplemente apagas el Mac Mini que falla y se puede sustituir por otro y el sistema global sigue funcionando.
- Ahorro: una vez inviertes en el hardware, que no vamos a engañar a nadie, es caro, pero ya puedes olvidarte de caras suscripciones a servicios de IA en la nube o clusters cloud como los de AWS, GCP, Azure, etc
Por supuesto, tienes también las ventajas agregadas de ejecutar modelos de IA en local como tendrías en cualquier otro caso independientemente del hardware, es decir, mayor privacidad y seguridad para los datos que manejas, sin compartir nada con empresas de terceros en la nube como OpenAI, Microsoft, Claude, etc. Y, como sabes, las herramientas de desarrollo para Mac están muy maduras, por lo que si quieres experimentar con modelos y desarrollar, es la plataforma ideal.
También te puede interesar aprender los fundamentos de redes para interconectar equipos en local.
Mac Minis vs GPU dedicadas

Por ejemplo, si comparamos un sistema con 4 nodos (4x Mac Mini con M4 @ CPU 10 núcleos, GPU 10 núcleos, Neural Engine x16 y 24 GB de RAM unificada) vs sistemas x86 (Ryzen 7, NVIDIA RTX 4080 Super, 4090 y uno multi-GPU uniendo dos RTX 4090 por NVLink, 64GB de RAM), con precios de unos 4000€ aproximados en ambos casos, para tener igualdad de precio, nos encontramos que:
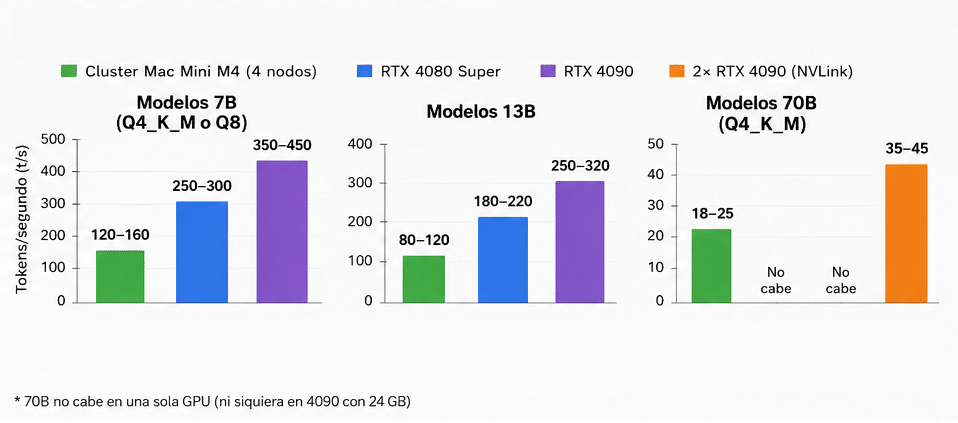
- Si nos fijamos en el rendimiento bruto en inferencia para modelos LLM, medida en tokens por segundo (t/s), se puede apreciar en el gráfico que en modelos como el 7B y 13B, pequeños, la GPU tiene una ventaja clara frente a las iGPUs del M4. En cambio, para modelos grandes como los de 70B o superiores, no pueden entrar en una sola VRAM de una GPU dedicada, y necesitan una doble tarjeta conectada por NVLink en este caso. También caben en el cluster Mac Mini, pero el rendimiento es bastante más pobre.
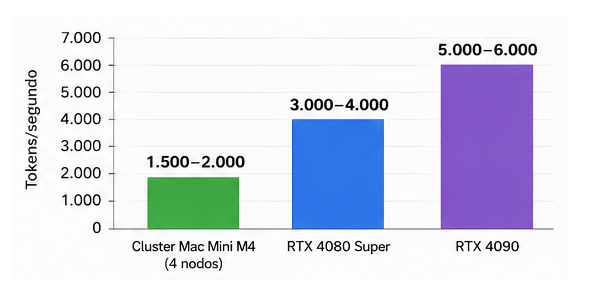
- Si nos centramos no en la ejecución de LLM, sino en el entrenamiento (Fine-Tunning Lora), también probando la velocidad en tokens/s, tenemos que el cluster Mac no tiene nada que hacer frente a los sistemas incluso con una única GPU. Y es que las iGPUs del M4 siguens iendo muy inferiores a una GPU dedicada.
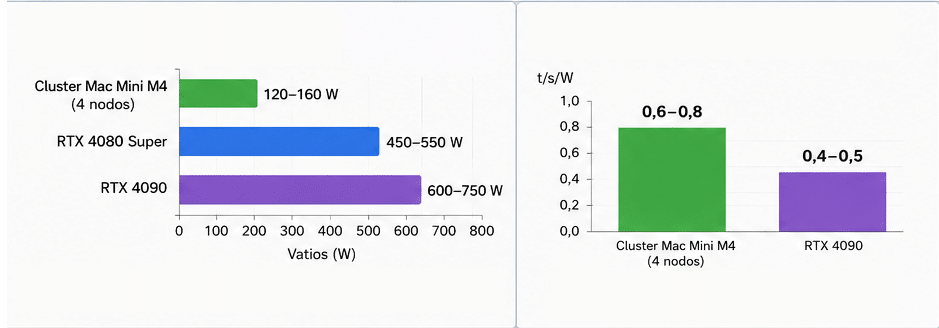
- Y en cuanto a consumo energético y eficiencia, vemos que en este caso, sí que el Mac Mini puede ganar por goleada. Las gráficas pueden consumir hasta 4-6 veces más. Como se aprecia en la gráfica de consumo energético (W) y en en el rendimiento por vatio (t/s/W).
Así que, si no te importa el rendimiento bruto y lo que buscas es mayor eficiencia para un sistema de alta disponibilidad, el nodo con Mac Mini es lo que buscas. Si lo que quieres es usar modelos muy pesados y necesitas rendimiento bruto, no te queda otra que usar GPUs dedicadas…
Cualquier duda, comentario o sugerencia, ya sabes…






