
El Qualcomm Snapdragon X Elite no es un procesador, es más que eso, se trata de un SoC que promete traer grandes novedades, beneficios y un aire fresco al mundo de los portátiles convencionales, más allá de los esenciales Chromebooks basados en ARM, pudiendo elegir un chip de alto rendimiento más allá de los x86. Por eso, vamos a ver qué esconde éste chip, sus secretos más profundos…
Índice de contenidos
Especificaciones técnicas del Snapdragon X Elite de Qualcomm
| Nombre del SoC |
Snapdragon X Elite |
| Nodo de fabricación |
4nm TSMC |
| ISA |
Arm’s v8.7-A |
| Microarquitectura de CPU |
Oryon |
| CPU |
Hasta 12 núcleos @ 3,8 Ghz (Turbo 4.2 – 4.6 Ghz) |
| GPU |
Adreno X1 con 4.6 TFLOPS @ 1.5 Ghz |
| NPU |
Hexagon con 45 TOPS |
| Memoria caché total |
42 MB |
| Controlador de memoria / SLC |
Hasta 64 GB de LPDDR5x 8448 MT/s con 8 canales y ancho de banda de 135 GB/s |
| Almacenamiento soportado |
NVMe PCIe 4.0 y UFS 4.0 |
| Sensing Hub |
Sí |
| ISP |
Spectra Dual ISP |
| Secure Processing Unit |
Sí, con Microsoft Pluton TPM |
| Conectividad |
X65 5G Modem-RF FastConnect 7800 |
| Tipo de chip |
Monolítico |
| TDP (TPL1 a TPL2) |
23 a 80W |
También te puede interesar conocer los mejores portátiles del mercado
Nomenclatura de Qualcomm para la Generación 1

El nuevo Snapdragon X Elite pertenece a la Gen 1, y ha cambiado su nomenclatura respecto a otras versiones previas. Para conocer cómo se marcan, es tan simple como:
| Núcleos CPU | Turbo todos los núcleos | Turbo en 2 núcleos | GPU TFLOPS | NPU TOPS | Total memoria caché en MB | MMU | |
| Snapdragon X Elite | |||||||
| X1E-00-100 | 12 | 3.8 Ghz | 4.3 Ghz | 4.6 | 45 | 42 | LPDDR5X-8448 |
| X1E-84-100 | 12 | 3.8 GHz | 4.2 GHz | 4.6 | 45 | 42 | LPDDR5X-8448 |
| X1E-80-100 | 12 | 3.4 GHz | 4.0 GHz | 3.8 | 45 | 42 | LPDDR5X-8448 |
| X1E-78-100 | 12 | 3.4 GHz | 3.4 GHz | 3.8 | 45 | 42 | LPDDR5X-8448 |
| Snapdragon X Plus | |||||||
| X1P-64-100 | 10 | 3.4 GHz | 3.4 Ghz | 3.8 | 45 | 42 | LPDDR5X-8448 |
Como vemos, la serie Snapdragon X Gen 1 dispone de cuatro modelos, tres de ellos pertenecientes a la Snapdragon X Elite. Se identifican por estar marcados con el SKU X1E, seguida de un número de modelo, como se puede ver. Mientras más elevado sea el número, mejores prestaciones…
Microarquitectura del Snadpragon X Elite
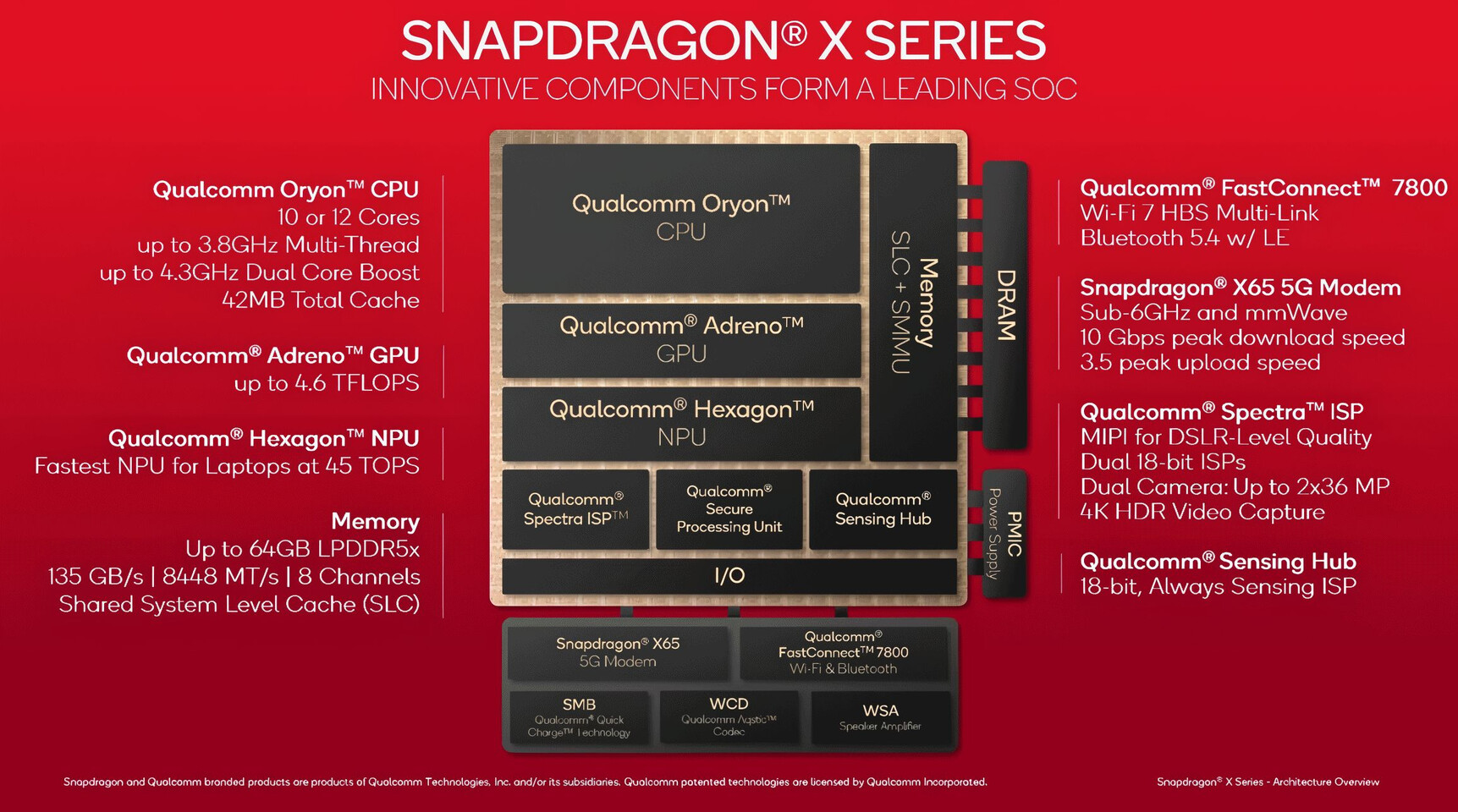
A grandes rasgos, el nuevo SoC Qualcomm Snapdragon X Elite es uno de los pasos más importantes dados en el desarrollo de los chips de esta compañía. En parte, es el fruto del trabajo de los ingenieros de Nuvia, especializada en chips ARM de alto rendimiento, y que Qualcomm adquirió precisamente para poder competir contra Apple, AMD e Intel.
La serie Snapdragon X de primera generación llega con dos variantes, una X Plus que tiene 10 núcleos de CPU, y otra X Elite con 12 núcleos de CPU, que es la que nos interesa aquí. De hecho, el Plus no es más que una versión capada del Elite por binning. Por tanto, ambos comparten bastantes cosas comunes.
TSMC ha sido el encargado de fabricar el chip bajo el nodo de 4nm, para conseguir mejoras en cuanto al switching de los transistores FinFET, y por tanto en la frecuencia de reloj, así como una reducción del consumo, y mayor densidad por unidad de superficie, algo vital para un chip que sigue siendo monolítico y que no usa ningún tipo de empaquetado 3D como Intel o AMD.
En el lado de Qualcomm, los diseñadores se han centrado principalmente en enfatizar el rendimiento y la eficiencia energética, para conseguir alargar la autonomía de la batería. Para que esto sea posible, han desarrollado una nueva microarquitectura denominada Oryon, descendiente de la vieja Kryo, en vez de usar directamente núcleos IP Arm Cortex-A. No obstante, se siguen basando en la ISA ARMv8, aunque no se han dado demasiados detalles.
Los núcleos de CPU se agrupan en clústeres de 4 núcleos cada uno, es decir, tres clusters para sumar un total de 12. Cada grupo de 4 está conectado con una unidad BIU (Bus Interface Unit) con el exterior. Esto permite dar vida a los clústeres según se demande en cada momento, permitiendo controlar el consumo.
Junto a la CPU también se ha incluido una GPU Adreno X1, con una nueva arquitectura para ofrecer un rendimiento superior a las anteriores, como la Adreno 750. También hay una NPU Hexagon con 45 TOPS de rendimiento, superior a todos sus contrincantes del sector por el momento.
Así mismo, el SoC integra también controladores de memoria RAM LPDDR5X con hasta 8 canales, 64 GB de capacidad máxima, y ancho de banda de 135 GB/s, y otras partes comunes de estos SoCs como la unidad E/S (I/O), el ISP Spectra, el Secure Processing Unit para cifrado y evitar side-channel attacks, el Sensing Hub, y modems para la conectividad.
CPU Oryon

La microarquitectura Oryon ha sido una gran aportación de los veteranos de Nuvia que se unieron a Qualcomm. El proyecto inicial se había titulado Phoenix, destinado a competir en servidores. Sin embargo, pronto se reorientó al mundo de los portátiles y se renombró como Oryon.
Esta microarquitectura ejecuta una ISA ARMv8.7A, de la que dependía este diseño en sus inicios, y que arraigó para esta Gen 1, aunque es de esperar que haya cambios al respecto en la Gen 2.
Como he dicho, se compone de 3 clústeres, cada uno con cuatro núcleos y una BIU. Cada clúster tiene su propio PLL para poder despertar o poner a dormir los núcleos de forma más flexible, buscando el mejor equilibrio entre rendimiento y consumo según la carga de cada momento.
SLC son las siglas de Single-Level Cell, mientras SMMU son las correspondientes a System Management Memory Unit.
Cada núcleo dispone de una memoria caché L1, con 192KB de I-Cache y una unidad Ltch que puede recuperar hasta 16 instrucciones por ciclo, pero no disponen de L2 propia, sino que se comparte cada L2 con los cuatro núcleos del clúster, y se va accediendo mediante sniffing cuando se necesita leer un dato almacenado en otro clúster. La caché L2 tiene penalizaciones de solo 17 ciclos de latencia si se produce un fallo en la L1, lo cual está bastante bien. La caché se ha rediseñado, es de tipo inclusivo, para permitir que la liberación sea más simple, sin necesitar que se tengan que trasladar a la L2 o eliminados de la L2 cuando se promueven hacia la L1. Todo gracias a un protocolo denominado MOESI.
La verdad es que ha llamado la atención lo grande que es cada clústerrespecto a otros núcleos anteriores, pero el motivo es que esa base de Nuvia, pensada para clúster de 8 núcleos para servidores, ha hecho que herede este «problemilla». Espero que se mejore esto en futuras generaciones, ya que ahora es entendible que hayan trabajado a destajo desde 2021 para adaptar un procesador para servidores para PC, algo así como lo que hizo Intel con el Pentium 4 Extreme Edition, que iba a ser inicialmente un Xeon, pero se vieron obligados a hacer este cambio por los avances de AMD.
Es curioso también que no se haya optado por núcleos de alto rendimiento y de alta eficiencia como en otros diseños. En este sentido, Qualcomm ha seguido una filosofía similar a AMD, desmarcándose de Intel y Apple.
El codificador del Front-end de Oryon es bastante ancho, capaz de trabajar con 8 instrucciones en un solo ciclo de reloj, más que los 6 de Intel y los 4 de AMD de sus últimos diseños. Además, no hay diferencias entre los decodificadores, todos son idénticos, simétricos, sin unos para instrucciones largas o especiales y otros para normales. Eso sí, se siguen traduciendo estas instrucciones en micro-operaciones, como en Intel y AMD, a pesar de que ARM es una RISC. Pero cada instrucción se traduce en hasta 7 microoperaciones, aunque la mayoría de ellas se traduce en una sola micro-operación.
El predictor de saltos también se ha mejorado bastante, para no penalizar demasiado en caso de fallo, con solo 13 ciclos de latencia para su recuperación. No obstante, no se han dado demasiados detalles al respecto del tamaño de la tabla de este predictor. Sí tenemos el tamaño del TLB L1, que tiene 256 entradas, con soporte para páginas de 4KB a 64KB.


Si nos vamos al Back-end del Oryon, vemos algunos importantes cambios, con un gran ROB para mejorar el paralelismo a nivel de instrucción en la OoOE. En principio, salvo instrucciones raras con más micro-operaciones, la tasa de extracción será la misma que la de entrada, es decir 8 por ciclo.
El renombre de registro también llama mucho la atención, con más de 400 registros disponibles para enteros y otros 400 registros vectoriales. Con 6 canales para números enteros y 4 canales para FP/vectores, así como otros 4 canales para Load/Store. Las operaciones enteras en las ALUs básicas pueden ejecutarse en un ciclo solo, mientras otras complejas en el MLA o FP/vector, necesitarán algunos ciclos más, por ejemplo, para instrucciones vectoriales Matrix, SVE, etc.
Por otro lado, la MMU o unidad de gestión de memoria del Oryon es bastante sencilla, con soporte para virtualización anidada, y con un ancho de banda posible de 135 GB/s para comunicarse con la DRAM principal.
Emulación
Hay algo muy interesante que destacar aquí, y es que el Snapdragon X Elite dispone de retoques en su microarquitectura para emulación. De esta forma, puede ejecutar software nativo en binarios para x86, así como los binarios nativos ARM. Una forma de no limitar la compatibilidad para algunos programas que no han portado sus proyectos a ARM.
La emulación la hace un software Prism, que es una especie de Rosetta 2 de Apple, pero en este caso para estos otros chips. El hardware dedicado a esto es algo más complejo que el de Apple, y está estrechamente relacionado con el proyecto o capa de traducción Prism desarrollado por Apple. Ambas compañías han trabajado conjuntamente para ello.
Básicamente la parte de hardware referente a la emulación dentro de Oryon se centra en mejorar el rendimiento para instrucciones de coma flotante x86, y donde más problemas existe, como las AVX2. La propia Qualcomm confesó que la traducción de instrucciones AVX a NEON es difícil, aunque se puede hacer, como ha demostrado Apple…
GPU Adreno X1

La GPU Adreno, que Qualcomm compró a AMD cuando ésta adquirió ATI, ha ido evolucionando hasta llegar a la Adreno X1, aunque no se trata de una arquitectura totalmente nueva. Es más bien una nueva revisión, representando la 7ª generación, con capacidades de trazado de rayos y soporte para DirectX 12 Ultimate completo.



Hay que recordar que Adreno ha estado muy relegada al ámbito de los dispositivos móviles con Android, un mundo diferente a Windows. Por tanto, han tenido que trabajar bastante en este aspecto, incluyendo algunas características fundamentales para la API gráfica de Microsoft, como la retroalimentación del sampler, soporte para sombreadores de malla, etc.
La GPU Adreno X1, para realizar estos trabajos, dispone de:
- Bloques de procesador de 6 shaders (SP). Cada SP se subdivide en dos micropipes o uSPTP.
- Cada uSPTP tiene sus propias unidades de textura, con 9 Texels por ciclo de reloj.
- Cada SP tiene 256 ALUs FP32. Es decir, 128 ALU por micropipe.
- Con un total de 1536 LUs.
- 16 EFU para manejar funciones tipo LOG y SQRT, u otras raras.
Esta arquitectura tiene sus semejanzas y diferencias con otras de Intel, AMD, NVIDIA o Apple. Por ejemplo, llama la atención las 6 unidades ROP, capaces de procesar 8 píxeles por ciclo cada una, lo que da un total de 48 px/s renderizados. También incluye una memoria scratchpad que la compañía llama GMEM de 3MB y 2.3 TB/s de ancho de banda, permitiendo que los ROPS no tengan que esperar o verse limitados por la latencia de memoria.
Por encima del GMEM, hay una caché de racimo de 128KB para cada par de SPs (384KB en total). Y por encima de eso también hay una caché L2 unificada de 1MB para la GPU. Finalmente, esto sale de la caché de nivel de sistema (L3/SLC), que sirve todos los bloques de procesamiento de la GPU. Y cuando todo lo demás falla, está la DRAM.
Para finalizar, hay que agregar que la Adreno X1 también incluye una MCU RISC que actúa como GMU o GPU Management Unit. Eso permite controlar el consumo energético, según las necesidades de cada momento…
NPU Hexagon

Hexagon es el nombre para una familia de procesadores de señales digitales (DSP o Digital Signal Processor) de Qualcomm. Puedes pensar que esto es incorrecto, ya que nos referios a la NPU, pero la verdad es que el QDSP se emplea para acelerar cargas de IA debido a que estas unidades que son bien conocidas como procesador central para tarjetas de sonido, también son perfectas para la IA dadas sus unidades de ejecución.
Cada versión de Hexagon tiene una ISA y microarquitectura, diferentes a las de la CPU y diferentes a las de la GPU. En el caso de esta revisión para el Snapdragon X Elite, tenemos un rendimiento de 45 TOPS, lo que es realmente impresionante, superando a sus competidores directos y permitiendo que Copilot se pueda ejecutar en local, algo que no se puede en los chips de AMD, Intel y Apple por el momento.
Hexagon 6 puede acelerar las cargas de IA gracias a las unidades MAC, que pueden despachar en orden hasta 4 instrucciones por ciclo. La Multiply-Accumulate Unit es una unidad de multiplicación-acumulación tan frecuente en aplicaciones de IA. Son básicamente operaciones de multiplicación, suma y acumulación. Y están especialmente optimizadas para trabajar con datos y precisiones bajas como las que usan frecuentemente la IA: INT8, FP16,…
No dudes en dejar tus comentarios…






