Strix Halo llega con la ambición de demostrar que un APU puede plantar cara a soluciones dedicadas para IA, mientras que DGX Spark juega en otra liga, más industrial y orientada a cargas masivas. El choque entre ambos mundos es fascinante: eficiencia extrema contra músculo puro. Aquí desgranamos qué aporta cada uno y por qué esta comparación importa más de lo que parece…
Índice de contenidos
Tabla comparativa de características Strix Halo vs DGX Spark
| Característica Técnica | AMD Strix Halo AI (Ryzen AI Max+ 395) | NVIDIA DGX Spark |
| Arquitectura | AMD Zen 5 (CPU) + RDNA 3.5 (GPU) | NVIDIA Grace Blackwell (Superchip GB10) |
| Núcleos de CPU | 16 núcleos / 32 hilos (Zen 5 completo) | Núcleos basados en ARM (Arquitectura Grace) |
| Frecuencia Máxima (CPU) | Hasta 5.1 GHz | Optimizada para rendimiento masivo en paralelo |
| GPU | AMD Radeon 8060S (40 Unidades de Cómputo) | GPU Blackwell dedicada integrada en placa |
| Rendimiento FP16 (GPU) | 20 a 60 TFLOPS (Dependiendo de optimizaciones) | 29,71 TFLOPS para alta densidad |
| Rendimiento Tensor / AI | Diseñado para inferencia mixta local | Hasta 1 PetaFLOP (FP4) mediante Tensor Cores de 5ª Gen |
| NPU Dedicada | Sí, AMD XDNA 2 (Hasta 50 TOPS) | No (Todo el cómputo de IA se delega a los Tensor Cores) |
| Memoria Sistema / VRAM | 128 GB LPDDR5X Unificada (Compartida CPU/GPU) | 128 GB LPDDR5X Unificada (Coherente CPU/GPU) |
| Ancho de Banda de Memoria | ~256 GB/s (Bus de 256 bits, 8 canales) | ~273 GB/s (Bus de 256 bits) |
| Capacidad de Modelos (Inferencia) | Modelos de hasta 200B parámetros (cuantizados) | Modelos de hasta 200B parámetros (cuantizados) |
| Capacidad de Fine-Tuning | Ideal para modelos ligeros y medianos (ej. 7B – 8B) | Soporta Fine-Tuning local de hasta 70B parámetros |
| Consumo Energético (TDP) | De 45W a 120W (Hasta 140W en modo Boost) | 140W a 170W. |
| Ecosistema de Software | AMD ROCm, Windows DirectML, LM Studio | NVIDIA CUDA, DGX OS, TensorRT, RAPIDS, NVIDIA AI Stack |
| Sistemas Operativos | Windows 11 y Linux (Ubuntu / RHEL) | NVIDIA DGX OS (Solo Linux) |
| Redes y Conectividad | USB4 (40Gbps), PCIe 4.0, Wi-Fi / Ethernet integrado | 10GbE, ConnectX-7 SmartNIC, Wi-Fi 7, Bluetooth 5.3 |
Tenemos que el sistema de AMD tiene un precio de unos 3999€ y el sistema de NVIDIA parte de unos 4679€.
AMD Strix Halo AI vs NVIDIA Grace Blackwell: Arquitecturas al detalle
Tenemos dos arquitecturas diferentes, por un lado tenemos una APU, en el caso de AMD, y por otro lado tenemos un sistema de CPU y una GPU dedicada. Dos conceptos pensados para casos específicos diferentes, como te comentaré más adelante.

Por un lado, tenemos el AMD Strix Halo AI:
- Incluye una CPU de 16 núcleos basados en la microarquitectura Zen 5 (AMD64, x86-64), lo que significa que puede ofrecer un buen rendimiento en cargas convencionales, no solo en IA.
- Une una iGPU basada en RDNA 3.5 con hasta 40 CUs que ofrecen un gran rendimiento, equivalente a incluir una GPU dedicada decente en el mismo silicio que la CPU, para formar esta APU.
- También tiene una NPU dedicada exclusivamente a cargas de IA que supera los 50 TOPS, y basada en la arquitectura XDNA 2. Por tanto, tenemos CPU+GPU+NPU.
- Subsistema de memoria con hasta 128 GB de memoria unificada para los tres tipos de unidades de procesamiento y basado en el estándar LPDDR5X. También se incluye una banda bastante ancha y una Infinity Caché de 32 MB integrada, mitigando la latencia cuando las otras unidades compiten con la GPU por el ancho de banda del sistema.
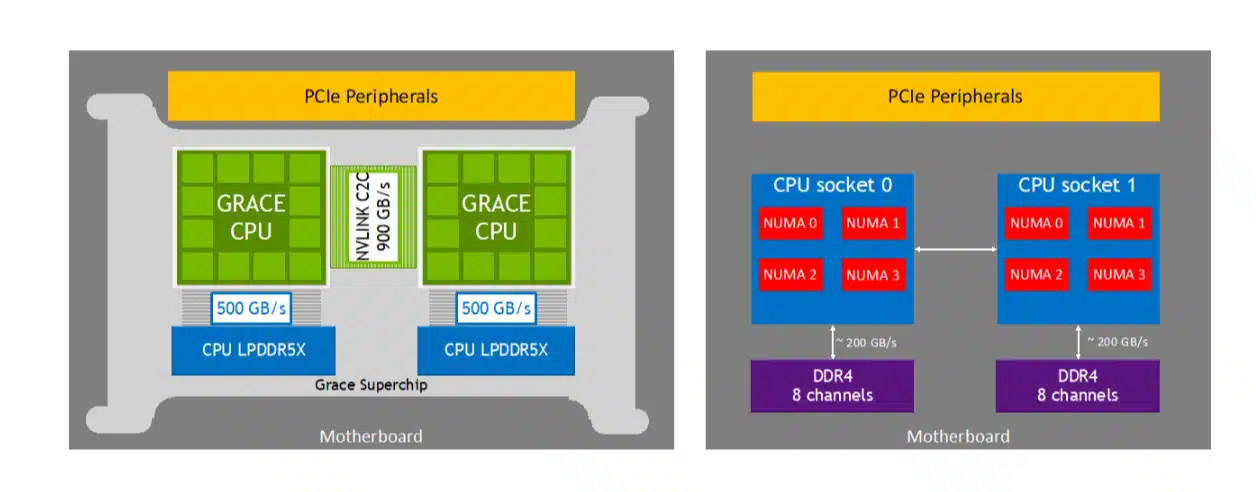
Si nos centramos ahora en el producto de NIVIDIA, encontramos que Grace Blackwell del DGX Spark, tiene:
- CPU basado en la microarquitectura Grace (a su vez basada en ARM Neoverse V2 con soporte para ISA ARMv9 y extensiones vectoriales SVE2. Este procesador tiene una gran eficiencia, con un rendimiento por vatio enorme, y se ha optimizado para gestionar la orquestación de tokens y pipelines paralelos de datos hacia la GPU que acelera estas cargas de IA.
- Junto con Grace está la GPU Blackwell, que no es una GPU convencional, sino que es más bien un sistema de Tensor masivo. Cuenta con núcleos CUDA y núcleos Tensor de 5ª Generación, con soporte nativo para precisiones ultra-bajas tipo FP4 y FP8 tan cruciales para los modelos Transformer cuantizados.
- Para enlazar ambos chips, ya que en este caso no es una APU, sino que están separados, se cuenta con un enlace NVLink-C2C que comunica Chip-to-Chip mediante una interconexión de hasta 900 GB/s.
- El subsistema de memoria en este caso es una memoria unificada también, capaz de mantener la coherencia y alta velocidad para alimentar tanto a la CPU como a la GPU. También se basa en una LPDDR5X, y aunque tiene 128 GB, se puede escalar hasta varios Terabytes en servidores. Se ha diseñado de tal forma que elimina la necesidad de transferir datos a través de buses lentos entre la memoria del sistema y la VRAM de la GPU que ocurre en un sistema de GPU convencional.
Comparativa de aceleradores para IA: pruebas de rendimiento

Ahora bien, una vez conocemos ambos productos, vamos a ver cuál puede ganar la batalla, si es que hay un claro ganador. Para eso, vamos a someterlos a algunas pruebas y comparar datos:
También te puede interesar nuestra lista de portátiles recomendados con hardware de nueva generación.
Rendimiento para entrenamiento
En las métricas orientadas al cálculo matricial masivo necesario para optimizar algoritmos, entrenar redes locales o realizar Fine-Tuning (ajuste fino), tenemos datos muy curiosos:
- AMD Strix Halo MiniPC (Ryzen AI MAX+ 395) puede alcanzar un rendimiento de cómputo de 59.4 TFLOPS en FP16/BF16 en teoría, pero en la realidad, con bibliotecas como hipBLASLt bajo ROCm, la potencia de ejecución matricial sostenida es de 36,9 TFLOPS. En capacidad de ajuste fino, puede realizar ajustes tipo LoRA en modelos de hasta 32B usando 96 GB de memoria gráfica asignada.
- NVIDIA DGX Spark (GB10 Superchip) los datos son más prometedores, con rendimiento en cómputo matricial Tensor de 225 TFLOPS (FP8) y 900 TFLOPS (FP4), y por encima de los 100 TFLOPS para FP16. Con el ajuste fino, soporta de manera nativa optimizaciones complejas en modelos de hasta 70B, casi el doble que AMD.
Otro punto positivo para DGX Spark es que se puede agrupar en clusters multi-nodo para mayor escalabilidad, agrupando varios equipos conectados mediante ConnectX-7 SmartNIC de 10 GbE. En el caso del miniPC de AMD, no viene preparado para ello.
Rendimiento sostenido bajo cargas mixtas
| Métrica / Benchmark | AMD Strix Halo (Ryzen AI MAX+ 395) | NVIDIA DGX Spark (GB10) |
| Potencia Bruta de IA (Total) | 126 TOPS Combinados (50+ NPU / 76 iGPU) | 1 PFLOPS(unos 1000 TFLOPS) en FP4 |
| Modelo Ligero: Phi-3.5 (Inferencia) | ~61 tokens / segundo (Mixto NPU + iGPU) | >210 tokens / segundo (Uso de TensorRT) |
| Modelo Medio: Llama 3 8B (Q8) | ~42 tokens / segundo | ~145 tokens / segundo |
| Modelo Pesado: Qwen 32B (Q8) | ~6,23 tokens / segundo | ~38 tokens / segundo |
| Límite de Parámetros Local | Hasta 70B (Asignando hasta 96 GB como VRAM) | Hasta 120B / 200B (Soporte nativo FP4/FP8) |
Este escenario evalúa la capacidad de procesamiento simultáneo (CPU realizando tareas lógicas complejas mientras la GPU o NPU aceleran flujos de datos secundarios). En este caso, destaca especialmente el NVIDIA, que bate al AMD por mucho en todos los sentidos bajo cargas mixtas sostenidas.
Consumo y eficiencia energética
Relación entre la energía consumida y la entrega de potencia por unidad de trabajo, el miniPC de AMD puede obtener una pequeña ventaja, aunque visto lo visto en el rendimiento, esa ventaja prácticamente pasa desapercibida:
- NVIDIA DGX Spark: consigue un consumo total del sistema de unos 240W totales, siendo 140W de ellos para el Superchip GB10. Esto lo deja con un ratio de eficiencia de 4.16 TFLOPS por vatio consumido en FP4.
- AMD Strix Halo AI: solo la APU tiene un consumo de hsta 120W, y el sistema total puede alcanzar picos de entre 230 y 330W, lo que resulta un ratio de eficiencia de unos 0.27 TFLOPS por vatio en FP16.
Elección según tipo de proyecto
La arquitectura ideal no depende únicamente de la potencia bruta, sino del ecosistema, las restricciones de presupuesto y el despliegue físico del proyecto en el que vayas a trabajar. Para facilitarte las cosas, decir que:
- AMD Strix Halo AI: elige este producto siempre que vayas a usarlo para Edge Computing y desarrollo de IA local, y en caso de que desees trabajar con Windows 11.
- NVIDIA DGX Spark: solo permite trabajo con Linux, y no está tan centrado en un producto genérico, sino más específico para IA, así que si buscas potencia bruta para entrenamiento y para ejecución en local de modelos grandes, la mejor opción es ésta.
Deja tus comentarios o dudas…