
Gigabyte AI TOP ATOM es un Mini PC construido para trabajar con Inteligencia Artificial, y este modelo en concreto es una preparación propia de Gigabyte basada en la versión NVIDIA DGX Spark, con exactamente la misma plataforma en su interior.
Cuenta con chip Nvidia GB10 Blackwell, 128 GB de RAM, 4 TB de SSD y sistema operativo Linux Ubuntu sobre el que podemos instalar aplicaciones como el panel de control de Nvidia AI Software o la App Gigabyte AI TOP Utility que nos facilitarán mucho la interacción.
Agradecemos a Gigabyte haber confiado en nosotros al prestarnos este equipo para su análisis.
![]()
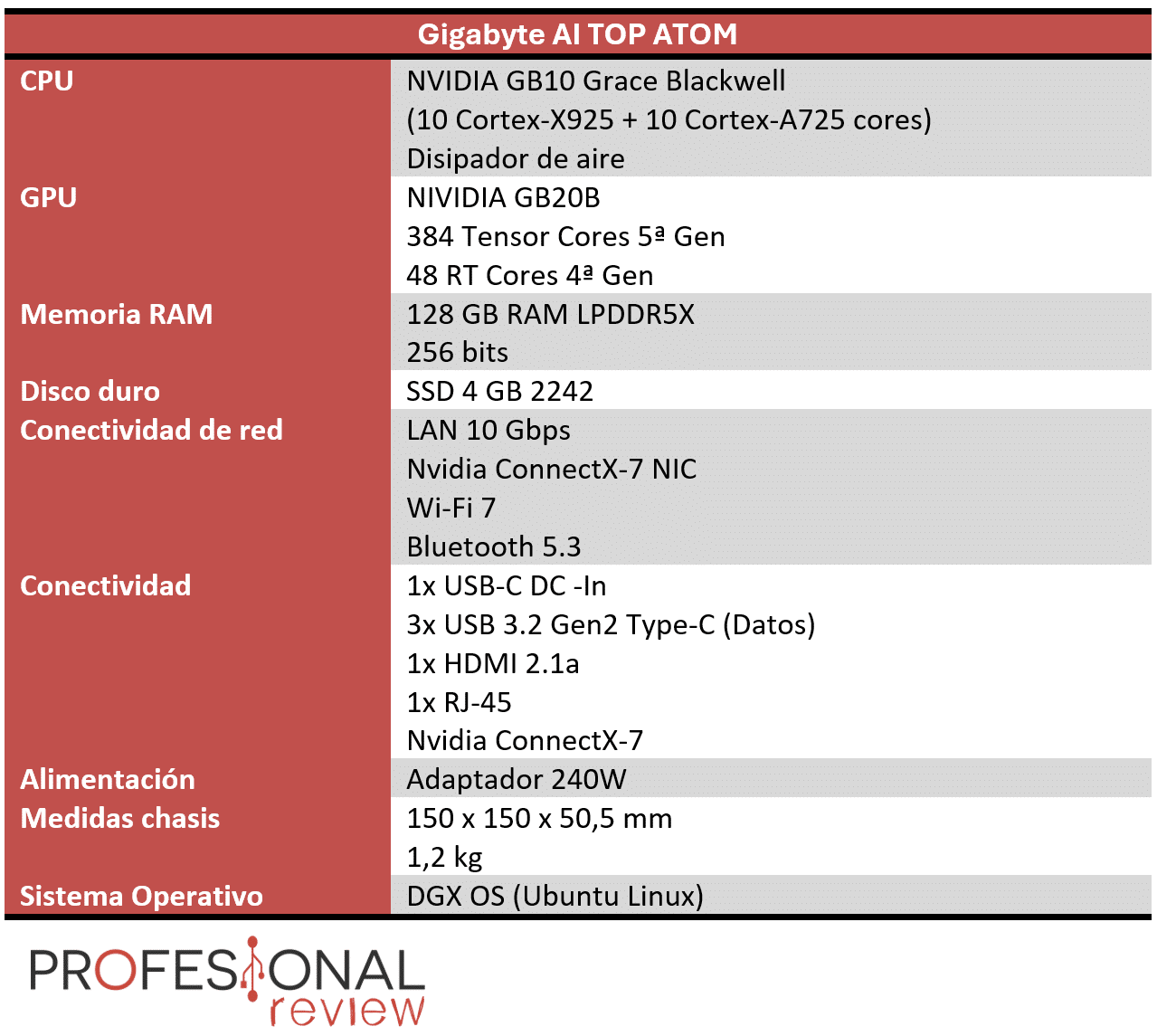
Gigabyte AI TOP ATOM características técnicas
Unboxing

Gigabyte AI TOP ATOM se presenta, como cualquier equipo, en su propia caja de cartón rígido con acabado liso y colores referentes a Nvidia. Dentro, tenemos buena protección mediante moldes de cartón y bolsas de aislamiento para el equipo.

El contenido de la caja será el siguiente:
- Gigabyte AI TOP ATOM
- Adaptador de alimentación con enchufe americano
- Manual de usuario
Análisis externo

Empezamos por lo más básico, el diseño del Gigabyte AI TOP ATOM, que consiste en una pequeña caja cuadrada de apenas 15 cm de lado y 5 cm de alto, con cubierta de aluminio, pesando menos de 1,5 kg.

En sus caras no tenemos absolutamente nada de decoración ni aberturas, pero sí que lo hace en el frontal, donde encontramos un panel de rejilla con el distintivo de la marca, cuya intención es la de proporcionar entrad de aire al disipador.

En el lado derecho tenemos una ranura Kensington para candados de seguridad, mientras que en la parte trasera, además de los puertos, también se encuentra una segunda rejilla para expulsar el aire caliente.

La zona inferior consta de una doble cubierta con apoyos de goma antideslizante. Dichas patas se deben despegar en las esquinas si queremos acceder a los tornillos que proporcionan acceso al interior. No disponemos de compatibilidad con soportes VESA.
Panel de puertos y conectividad
Todos los puertos del Gigabyte AI TOP ATOM se encuentran en el panel trasero, siendo exactamente los mismos que en el Nvidia DGX.

Tenemos:
- Botón de encendido
- 1x USB Type-C DC-In (alimentación)
- 3x USB 3.2 Gen2 Type-C (datos y vídeo)
- HDMI 2.1a
- RJ-45 10 Gbps Ethernet
- 2x Puertos ConnectX-7
Tratándose de un equipo diseñado para trabajar durante horas, una interfaz USB-C de alimentación no es lo más aconsejable desde el punto de vista de la seguridad, ya que fácilmente podemos tirar accidentalmente del cable y apagar el equipo.
Si bien es cierto que, desde el punto de vista de la comodidad y compatibilidad, sí que es una buena elección.
No disponemos de puertos USB-A, todos son USB-C, por lo que conectar periféricos básicos implicar usar un dock o conversores si es que nuestro ratón o teclado cuenta con USB-A.
De igual forma, es un equipo que puede usarse en modo escritorio con monitor propio mediante HDMI. Para usar Displayport debes utilizar la conexión USB C con un HUB o adaptador a esta conexión.
El apartado de red está tremendamente potenciado, dado que es un equipo que probablemente en la mayoría de casos lo usemos de forma remota o mediante línea de comandos.

Por eso, tenemos una interfaz Ethernet de 10 Gbps conectado a un Lane PCIe Gen4 y tarjeta de red MediaTek Wi-Fi 7 conectada a un Lane PCIe Gen3, con Bluetooth 5.3.
Destaca especialmente la doble interfaz de red QSFP56 controladas por una tarjeta SmartNIC NVIDIA ConnectX-7, que a su vez se conecta a partir de 2 enlaces PCIe Gen5 x4.
Proporciona un ancho de banda teórico de 400 Gbps, pero limitado a 200 Gbps debido a la configuración de carriles del equipo. Están pensados para conectar un segundo Gigabyte AI TOP ATOM y duplicar la capacidad de cómputo.
Análisis interno
Extraemos, primero la cubierta central interior del Gigabyte AI TOP ATOM, y luego la segunda cubierta retirando los tornillos pertinentes.

El equipo se presenta en un solo bloque de hardware con las dos antenas Wi-Fi integradas en la cubierta extraíble, mientras que el SSD está plenamente accesible retirando dicha cubierta, en lo que sería la cara trasera de la placa base.
Ésta parte del equipo se encuentra cubierta mediante un robusto bloque de aluminio de protección y aislamiento.

Dispuesto en la otra cara, tenemos el disipador compuesto por dos ventiladores tipo blower y un difusor aleteado que extrae todo el calor del hardware. No lo hemos retirado, pero bajo él descubriríamos que los 8 chips de RAM también están en contacto con él para ser enfriados.
Centrándonos en la unidad de procesamiento, el Gigabyte AI TOP ATOM cuenta con un Nvidia GB10 Blackwell Superchip, en el cual se integran la CPU y GPU.

La parte de CPU consta de 20 núcleos ARM con arquitectura Big Little heterogénea, divididos en dos clústeres de 10 núcleos, ambos trabajando a frecuencias diferentes con distinta capacidad de caché.
El primer clúster suma 5 núcleos de rendimiento Cortex-X925 a 3900 MHz, 5 de eficiencia Cortex-A725 a 2808 MHz y un bloque de caché L3 de 8 MB, mientras que el segundo clúster tiene 5 A725 a 2860 MHz y 5 X925 a un máximo de 4004 MHz, esta vez con 16 MB de RAM. Los núcleos más rápidos son los 15 – 19.
Cada núcleo Cortex X925 cuenta con bloques de 2 MB de caché L2 por núcleo y caché L3 de 64KB-I + 64 KB-D, mientras que los Cortex A725 cuentan con caché L2 de 512 KB e idéntica caché L1.
En cuanto a la configuración de tarjeta gráfica tenemos el chip GB20B basado en Blackwell 2.0 con el proceso TSMC 3N. Está formada por 6144 CUDA Cores (Shaders), 384 Tensor Cores de 5ª Generación y 48 RT Cores de 4ª generación (un total de 48 SM). Trabaja a un reloj boost de 2418 MHz.
Además, el bloque de caché L2 consta de 50 MB, sumando 256 KB de caché L1 por SM, ofreciendo un rendimiento de hasta 1 petaFLOP en FP4. Cuenta con 1x NVENC y 1x NVDEC.

Todo ello viene acompañado de 128 GB de memoria RAM de tipo LPDDR5X integrada en placa mediante 8 chips que trabajan en un bus de 256 bits y proporcionan 272,2 GB/s de ancho de banda.
Con esta capacidad el equipo será capaz de cargar grandes modelos de IA directamente en memoria, pero lo ideal hubiera sido usar chips GDDR6 o GDDR7 para acelerar aún más los procesos, aunque claro, el precio sería muy superior.
Todavía nos queda por ver la unidad de almacenamiento, que es un SSD de 4 TB en formato 2242 conectado a 4 carriles PCIe Gen5. Cuenta con una enorme capacidad de serie para almacenar los pesados modelos de IA que descarguemos.
Todo ello se mueve con una fuente de alimentación de 240W mediante adaptador externo de no excesivo tamaño.
Sistema y uso del Gigabyte AI TOP ATOM
Gigabyte AI TOP ATOM se define como un super ordenador de IA en versión compacta de escritorio.

Posee en torno a 1 petaFLOP (1000 AI TOPS) de rendimiento en operaciones IA con precisión FP4, gracias a la arquitectura Blackwell, almacenamiento NVMe rápido, y la pila de software de IA de NVIDIA preinstalada, además de a app adicional Gigabyte AI TOP Utility.
Eso lo convierte en una estación de trabajo muy potente, más capaz que un PC normal, pero sin ser un centro de datos completo debido a sus limitaciones de alimentación y tamaño.
Este equipo está pensado para desarrolladores de Inteligencia Artificial y Machine Learning, investigación científica, startups que quieran implementar modelos IA propios o laboratorios educativos.
Proporciona un entorno unificado y amigable para la experimentación basada en IA, validando multitud de modelos, pudiendo realizar Fine-Tuning (Ajuste Fino) de modelos de gran tamaño, para adaptar modelos de miles de millones de parámetros a un entorno específico con nuestros propios datos, usando, por ejemplo modelos como Qwen3 8B
En todo caso, puede operar con grandes modelos IA en inferencia local, realizar procesamiento de datos científicos modelos 3D, fotorrealismo, creación de imágenes y robótica gracias a su GPU con núcleos Tensor y Ray Tracing.
Análisis de sistema y software Nvidia
El sistema operativo que corre bajo el Gigabyte AI TOP ATOM es el mismo que el usado en la máquina NVIDIA DGX, la versión -no custom- de esta plataforma, por así decirlo.
Se trata de un sistema denominado DGX OS que está basado en una versión de Ubuntu Linux, usando actualmente la versión Ubuntu 24.04 con Kernel Linux 6.8.
A su vez, se utiliza el sistema de contenedores con Docker para implementar aplicaciones de trabajo como pueden ser Ollama o SGLang. Esto complica un poco las cosas a la hora de efectuar instalaciones, pero hay una amplia comunidad detrás que siempre será de ayuda.
En él se han utilizado drivers optimizados para las GPU Nvidia, pudiendo utilizar la aceleración CUDA mediante el correspondiente toolkit, así como los núcleos Tensor y RT para integrarlos en el stack de software listo para IA / ML, donde se incluyen bibliotecas como cuDNN, cuBLAS, NCCL, entornos para contenedores (Docker + NVIDIA Container Toolkit), etc.
Se añaden herramientas de diagnóstico como Nvidia Dashboard y opciones de seguridad como el cifrado de la unidad de almacenamiento, cifrado en el sistema raíz, o la posible integración mediante red de dos equipos trabajando en paralelo.
Esta App de Nvidia monitoriza el uso del hardware básico en tiempo real, permite gestionar las actualizaciones del sistema, como drivers de Nvidia y firmware, dándonos acceso tanto local como remoto de forma gráfica mediante el navegador web.
Implementa la instancia Jupyterlab preconfigurada para empezar a trabajar en proyectos IA, inferencia o ML sin necesidad de instalar otros entornos.
Gigabyte AI TOP Utility
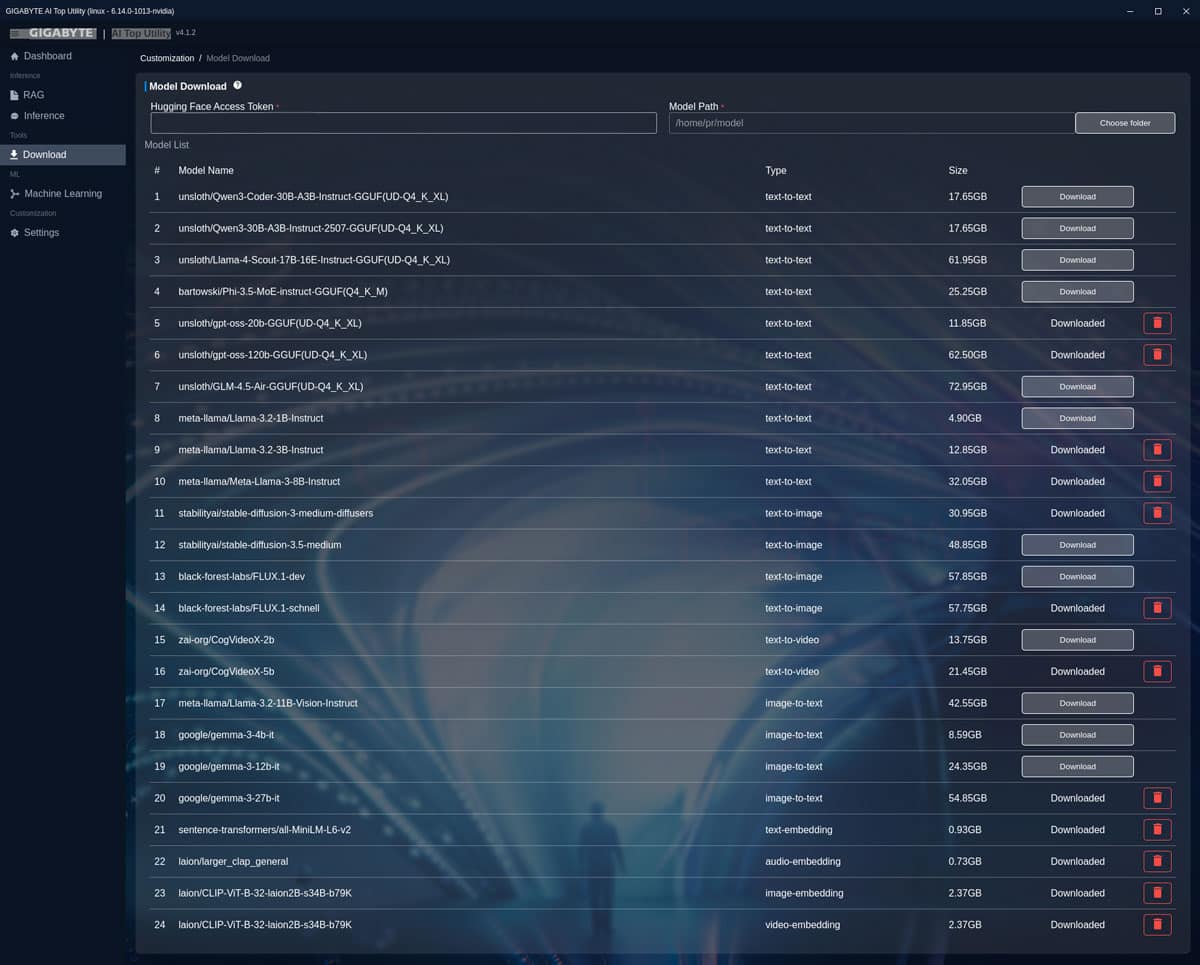
La marca añade su granito de arena al Gigabyte AI TOP ATOM implementando su propia aplicación para trabajar con modelos IA. Básicamente es una interfaz gráfica que nos facilita mucho la vida a la hora de descargar modelos y trabajar con ellos.
Permite monitorizar y gestionar de forma eficiente el consumo de memoria RAM y SSD en modelos de gran tamaño. Proporciona telemetría en tiempo real del consumo de hardware.
Desde ella podemos descargar automáticamente modelos de HuggingFace, previa creación de nuestra cuenta y obtención del token gratuito para su uso. Sin embargo, solamente podemos descargar un modelo a la vez (por el momento).
Ofrece la posibilidad de elegir múltiples opciones de ajustes, desde Estándar hasta Alta precisión, con soporte de subsistema de Windows para Linux. Cada modelo que ejecutemos permite distintos ajustes de CPU y GPU, límite de temperatura, además de poder fijar la cantidad de tokens de trabajo.
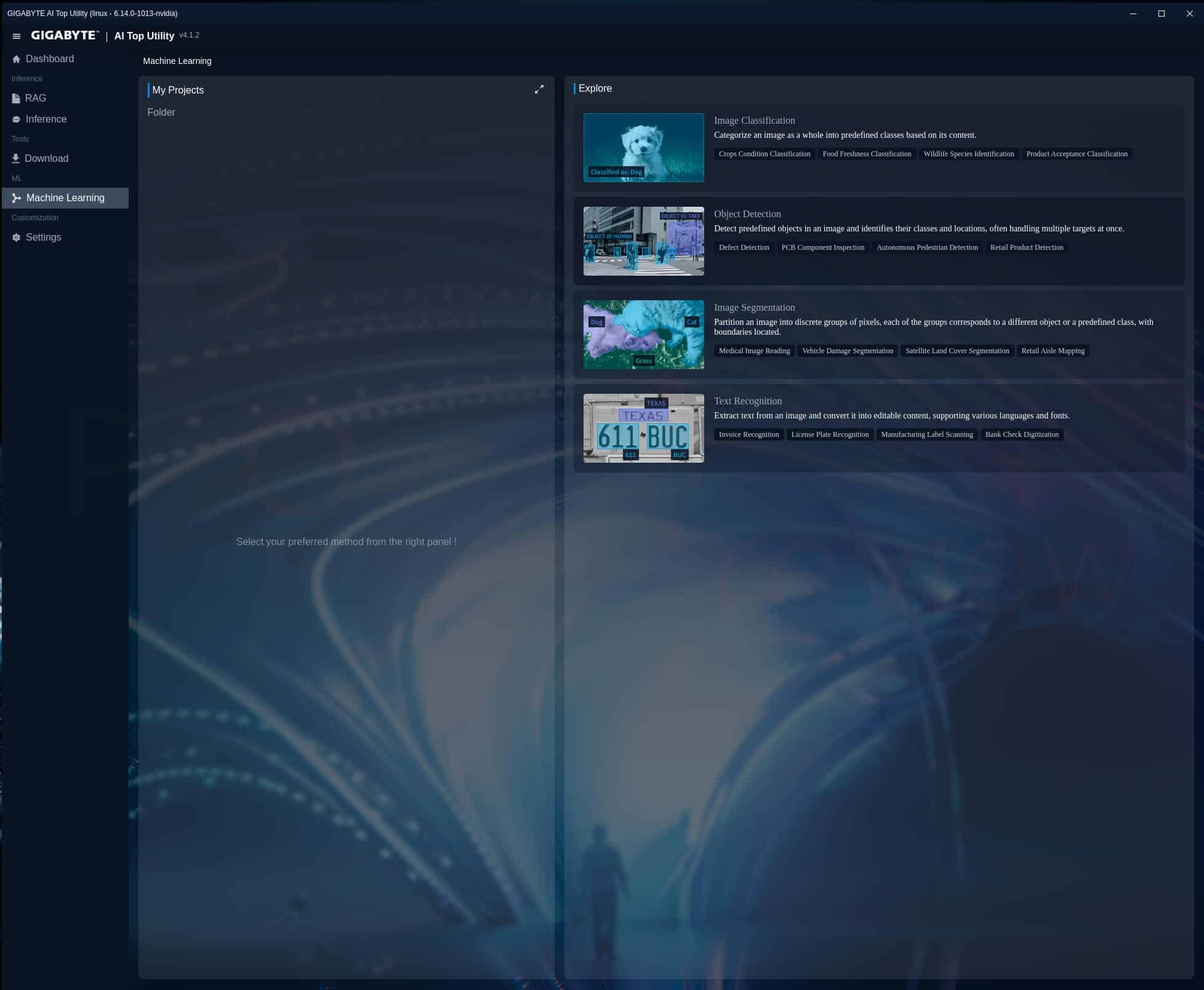
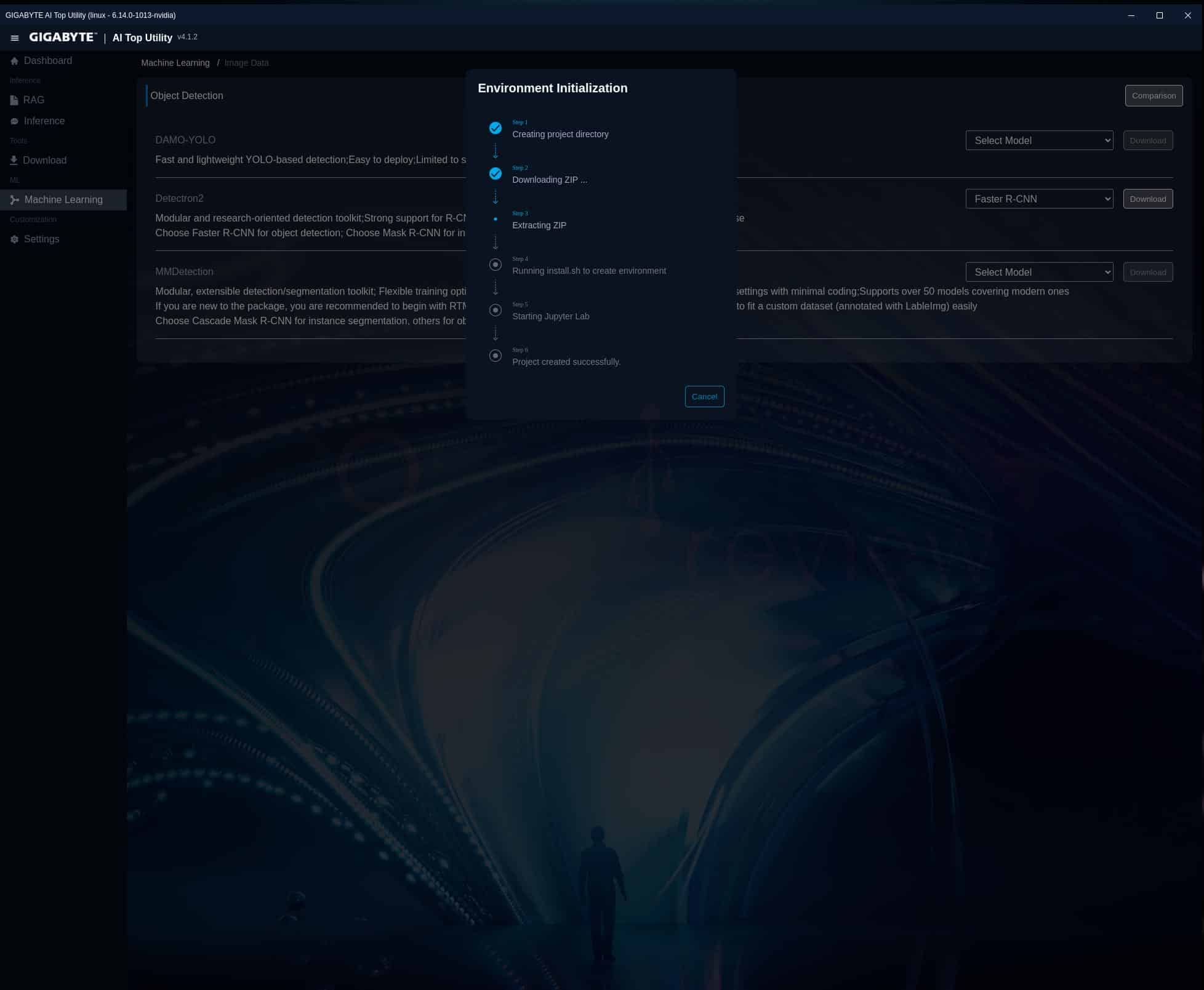
Podemos crear conjuntos de datos listos para ajustar mediante Fine-Tuning de LLM/LMM en los modelos de gran tamaño y potencia. Posee herramientas de entrenamiento de modelos con tecnología RAG
Puede convertir modelos (.safetensors, .bin) a GGUF con opciones de cuantificación (f32, f16, bf16, 8 bits) para un tamaño más pequeño o mejorar el rendimiento.
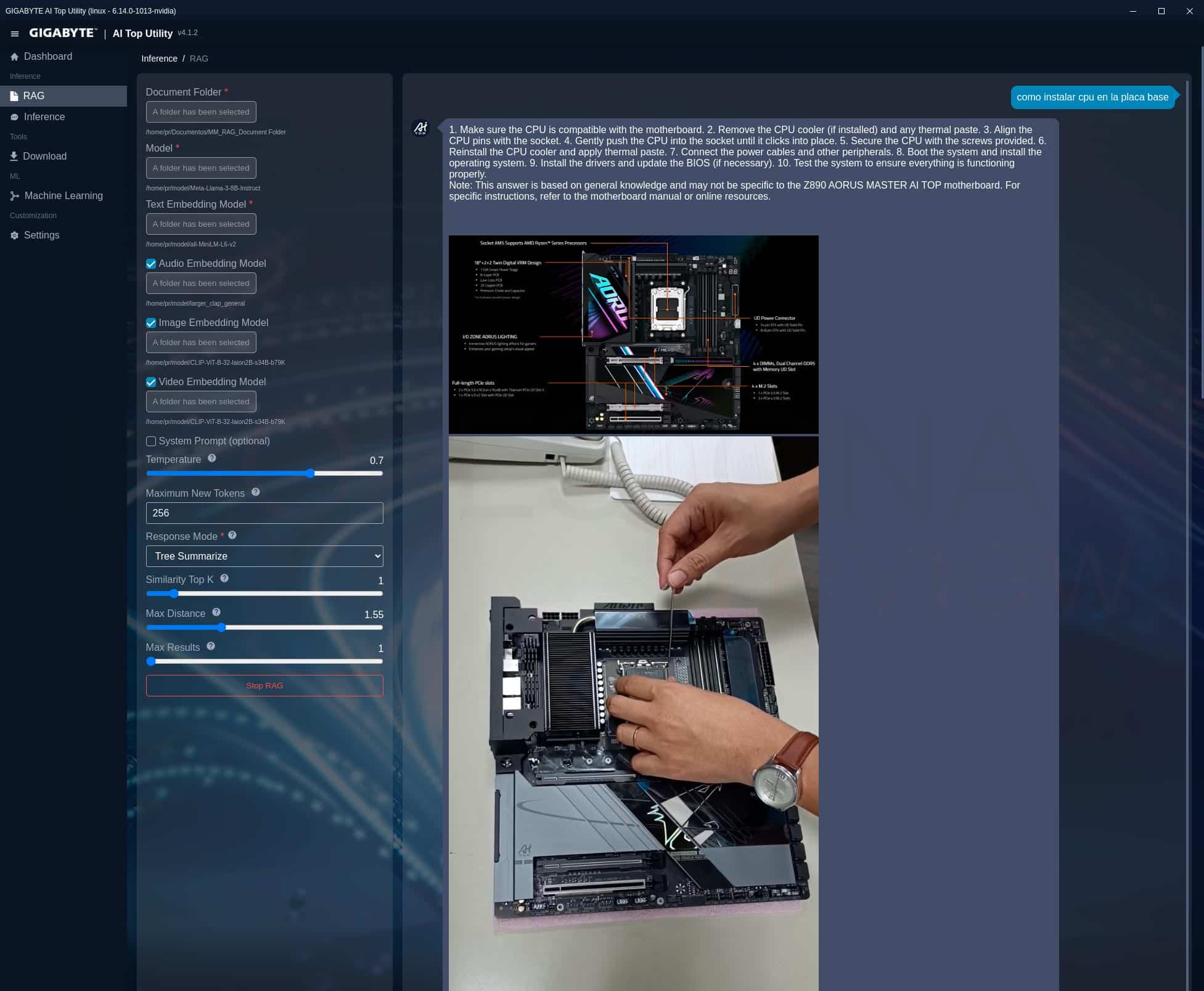
Instalar Ollama y Open WebUI en Gigabyte AI TOP ATOM
Aunque la utilidad anterior cubre muchos aspectos del trabajo del Gigabyte AI TOP ATOM, consideramos muy interesante instalar otras utilidades para el trabajo de inferencia con más modelos IA, como es el caso de Ollama, además de una interfaz gráfica para trabajar cómodamente tanto en local como de forma remota.
Al ser un sistema con docker, el proceso de instalación cambia un poco.
Instalar Ollama y modelos IA
Nos vamos a la página oficial de Ollama para instalar la utiliza con el comando en el terminal:
curl -fsSL https://ollama.com/install.sh | sh
Este paso es sencillo, solamente queda descargar los modelos de IA para Ollama desde la página oficial, mediante el terminal de comandos, por ejemplo:
ollama run gpt-oss:120b
Instalar Docker
Por suerte, Docker ya está instalado en ese equipo, así que simplemente podríamos verificar que funciona perfectamente aplicando el siguiente comando:
sudo docker run hello-world
Tras unos segundos, debe aparecer un mensaje diciendo que docker trabaja de forma correcta.
Instalar Open WebUI

El siguiente paso es instalar la interfaz gráfica en docker, encontrando los pasos a seguir en el siguiente enlace, aunque proporcionaremos pasos adicionales para que todo funcione.
Por ejemplo, necesitamos añadir nuestro usuario a docker para que le conceda los permisos pertinentes para instalar:
sudo usermod -aG docker $USER
Donde sustituimos $USER por nuestro usuario. Luego, salimos del usuario y volvemos a entrar para que los cambios surtan efecto.
Ya tenemos Ollama, así que usamos este comando:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Accedemos a la interfaz escribiendo en el navegador:
http://localhost:3000
Refrescamos hasta que aparezca una página de inicio, pulsamos abajo en “Comenzar” y creamos una cuenta de usuario para el acceso local y remoto.
Ojo, porque ahora necesitamos que los modelos descargados mediante comandos en Ollama aparezcan en la interfaz. Para ello debemos hacer unos cuantos pasos adicionales.
docker network inspect bridge
Debemos fijarnos en la IP que aparece en la línea “Gateway” normalmente será 172.17.0.1
Editamos un fichero de configuración
sudo nano /etc/systemd/system/ollama.service
Dentro, añadimos la línea adicional
Environment=”OLLAMA_HOST=172.17.0.1”
O la IP que hayáis obtenido
Para guardar, pulsamos en Ctrl + O y luego Enter. Para salir pulsamos Ctrl + X
Recargamos ollama con:
sudo systemctl daemon-reload
sudo systemctl restart ollama
Recargando la página, deberían aparecer los modelos descargados de Ollama.
Instalar Comfy UI para generar imágenes con IA
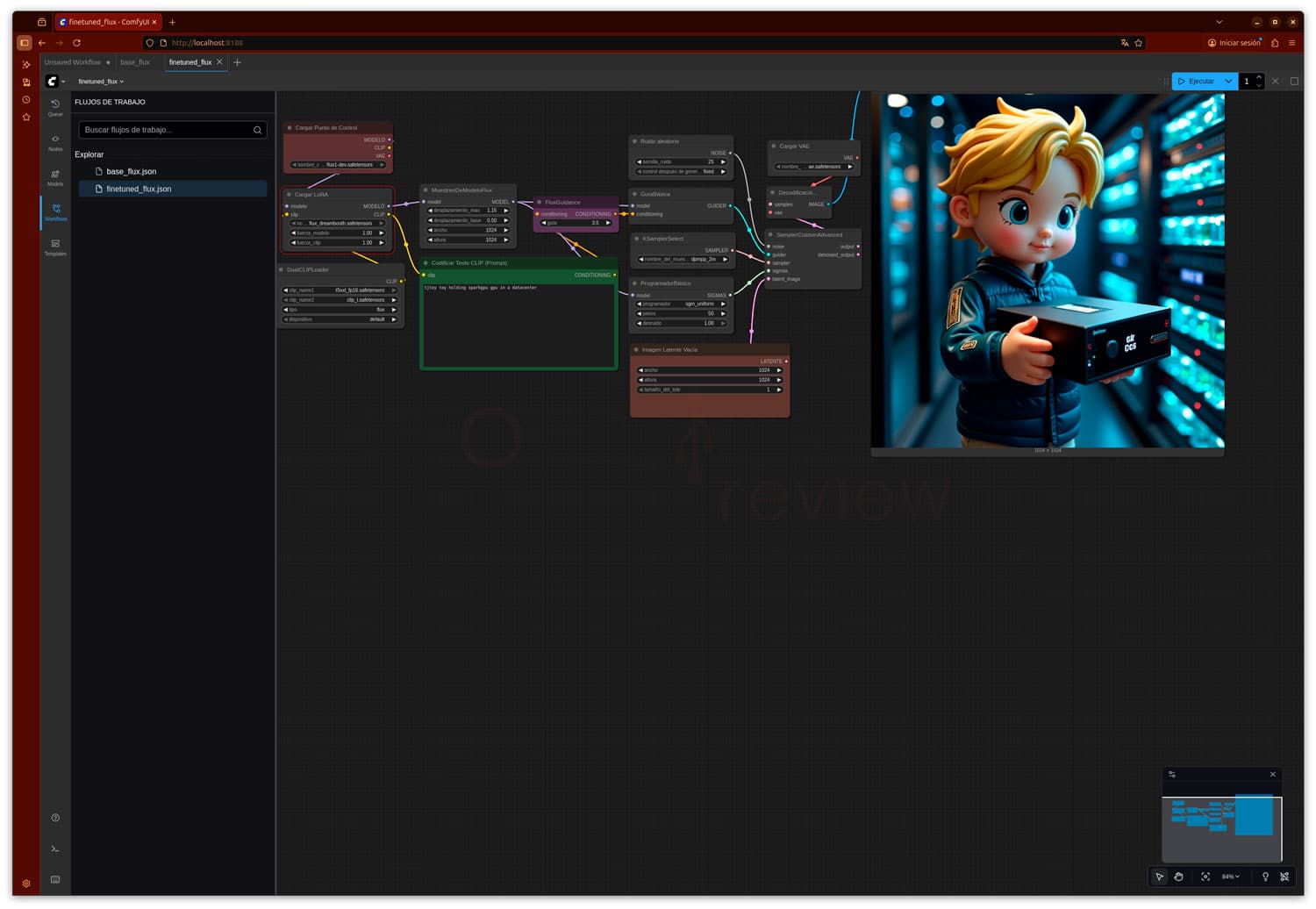
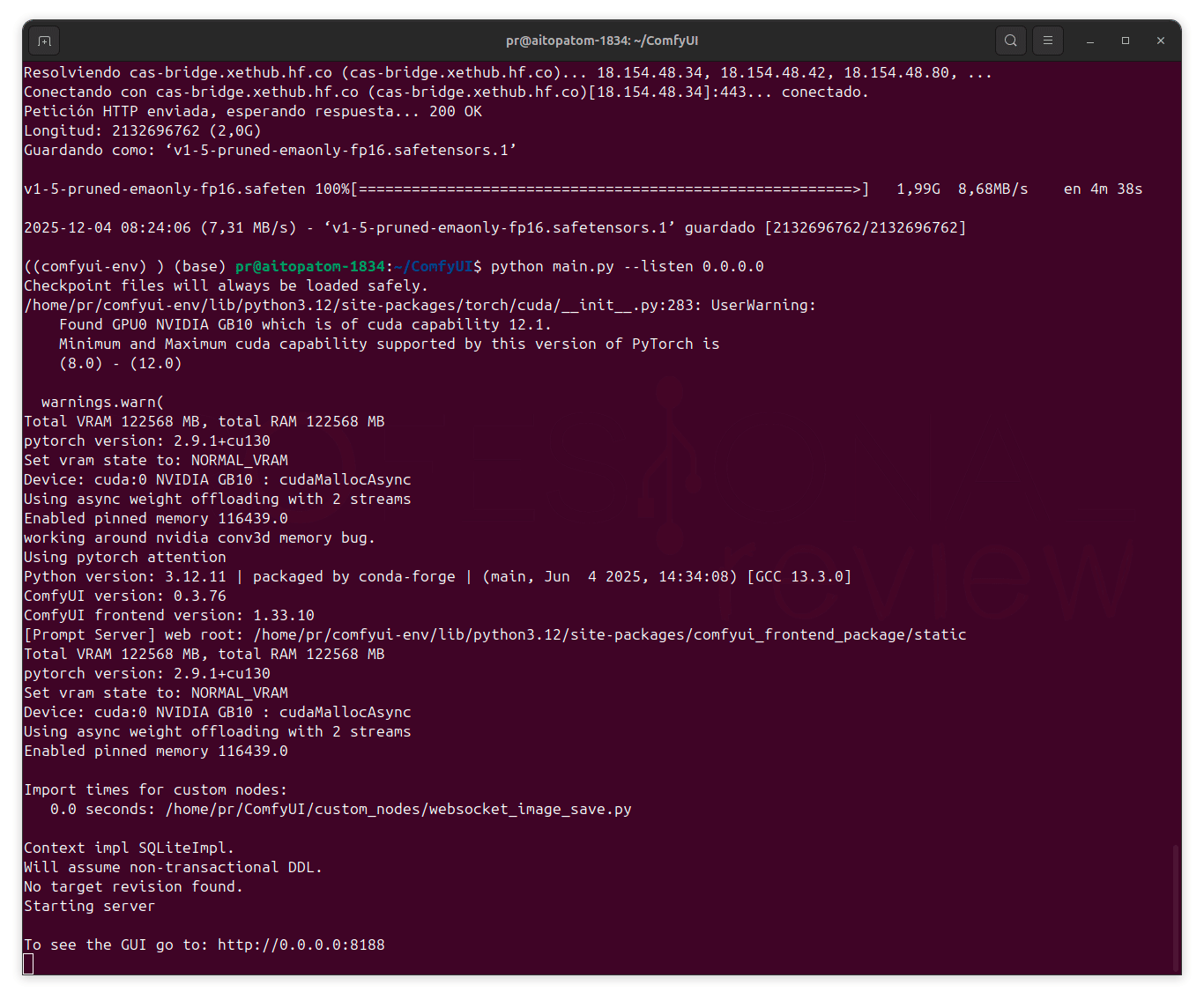
Comfy UI es otra aplicación bastante interesante para este Gigabyte AI TOP ATOM. Se trata de una aplicación de servidor web que permite trabajar con modelos basados en difusión como FLUX para la generación de imágenes con IA.
Lo más interesante es que posee una interfaz gráfica donde crear , editar y trabajar con flujos de trabajo guardados en JSON, realizando todo el trabajo localmente con la GPU del equipo.
Podemos instalar y empezar a usar Comfy UI siguiendo los pasos disponibles en el tutorial de Nvidia para DGX Spark, perfectamente aplicable a este equipo.
Hacer Fine Tuning de FLUX.1-dev 12B con Dreambooth LoRA
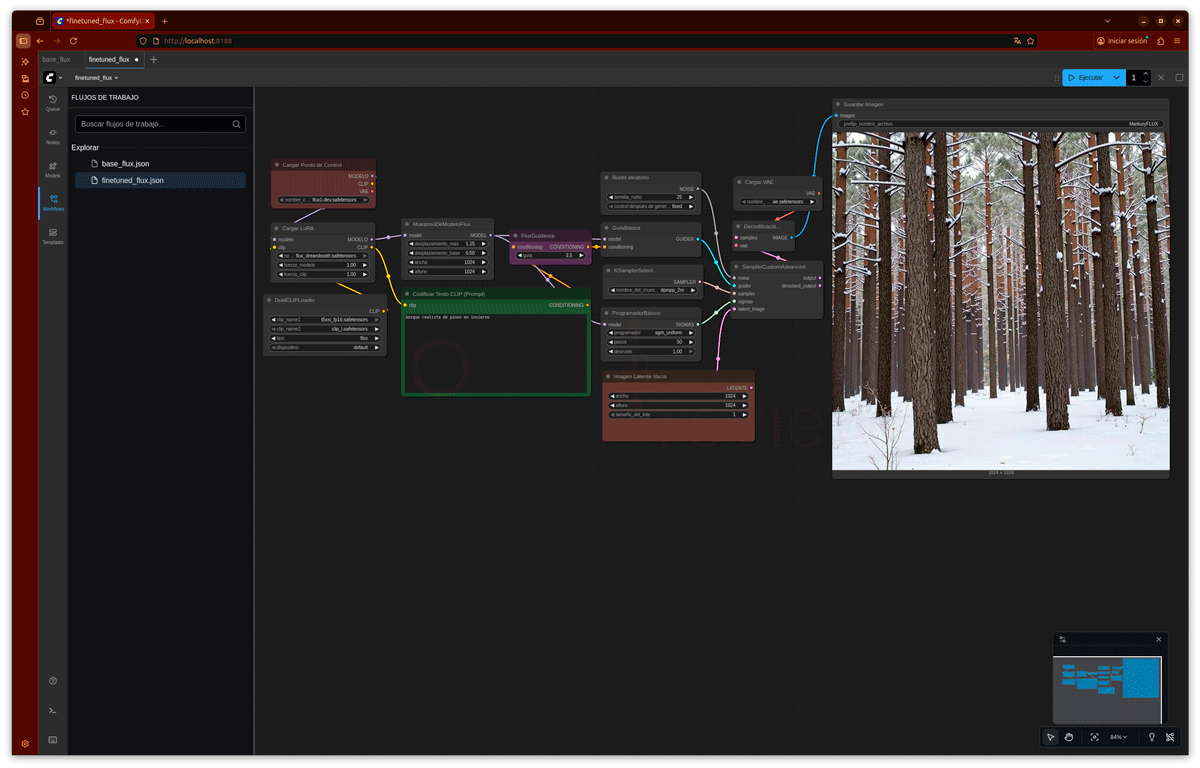
El siguiente paso interesante para poder crear nuestras propias imágenes es trabajar con un modelo de difusión estable afinado en nuestro equipo. Podemos hacer muchos, pero llevaremos a cabo el ejemplo que propone Nvidia con FLUX.1-dev 12B mediante Dreambooth LoRA.

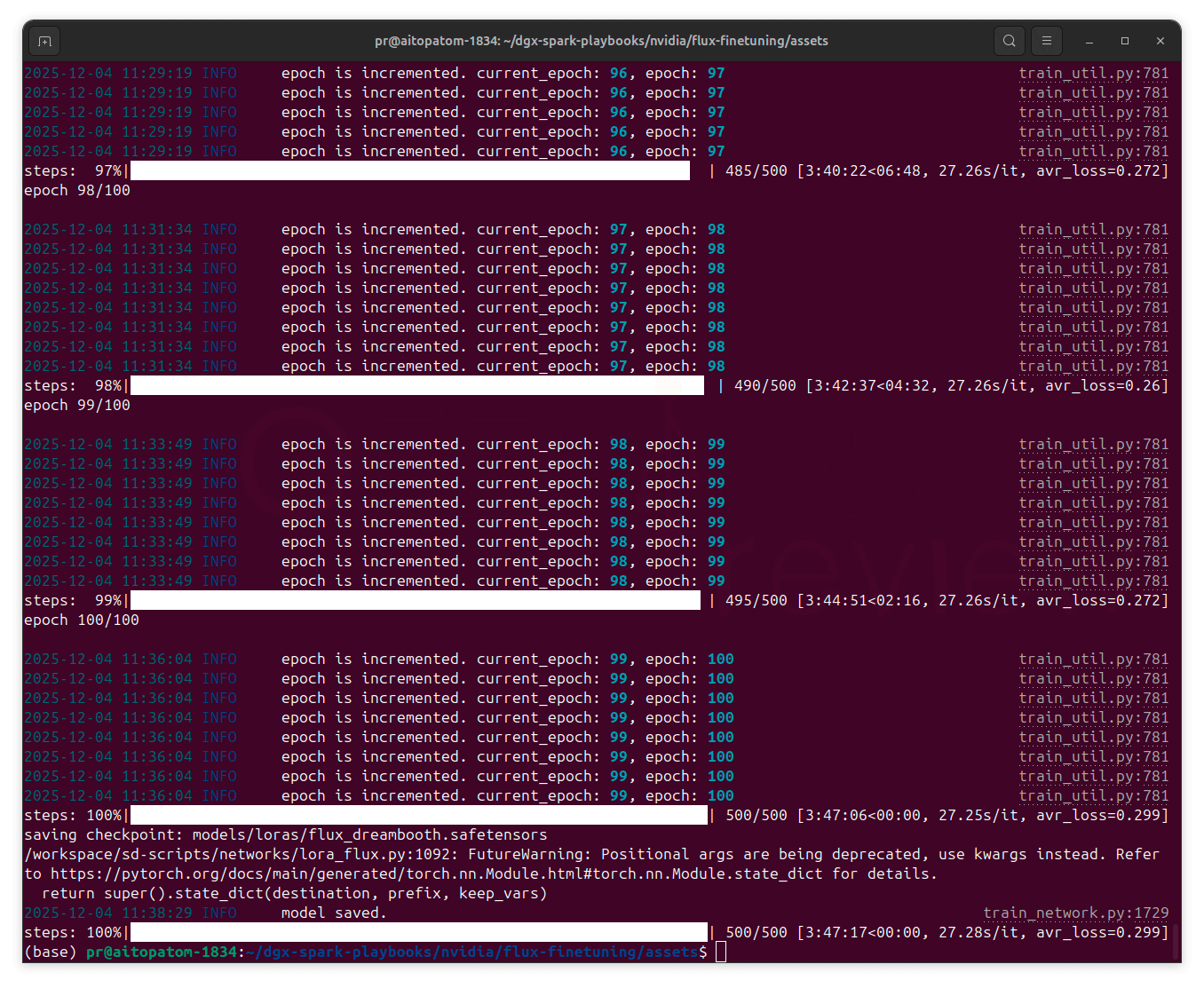
Debemos tener instalada Comfy UI para llevar a cabo los pasos finales. El tutorial completo de este proceso de fine tuning lo tendremos disponible en Nvidia para Spark. Tan solo debemos llevar a cabo los pasos explicados.
El modelo se ejecutará a través de la interfaz gráfica de Comfy UI, y con el conseguiremos un modelo capaz de generar imágenes que se ajusten a conceptos personalizados. Además del caso predefinido en el ejemplo de Nvidia, nosotros mismos podemos seleccionar recursos y flujos de entrenamiento propios.
El proceso de instalación llevará menos de media hora según la conexión a internet que tengamos para descargar los recursos, pero el entrenamiento del modelo ha necesitado esactamente 3:57 horas en completarse. Veremos los resultados en la fases de pruebas.
Pruebas de rendimiento de Gigabyte AI TOP ATOM
Para un equipo como este, las pruebas que debemos realizar tienen que ver con el uso de distintos modelos IA, comprobando su rendimiento en forma de tokens por segundo generados, para los modelos de inferencia texto-a-texto o en tiempo (segundos o minutos), para los modelos de generación de imágenes o vídeo.
De esta forma podemos medir qué tan rápido es el equipo, aunque esto estará supeditado al tipo de petición que le hagamos, ya que pueden ser más fáciles o difíciles, largas o cortas.
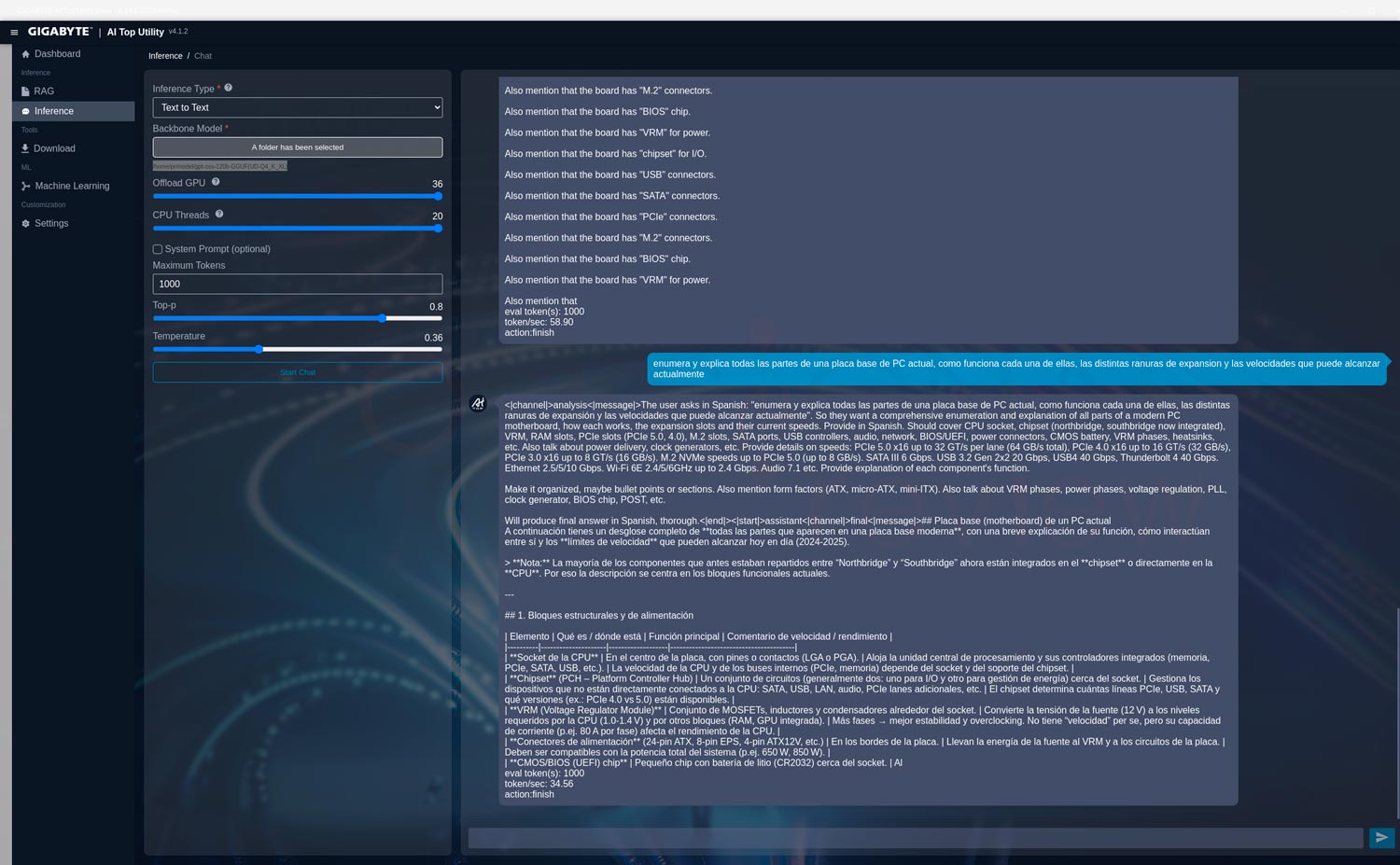
La pregunta texto-a-texto que usaremos para todos los modelos será:
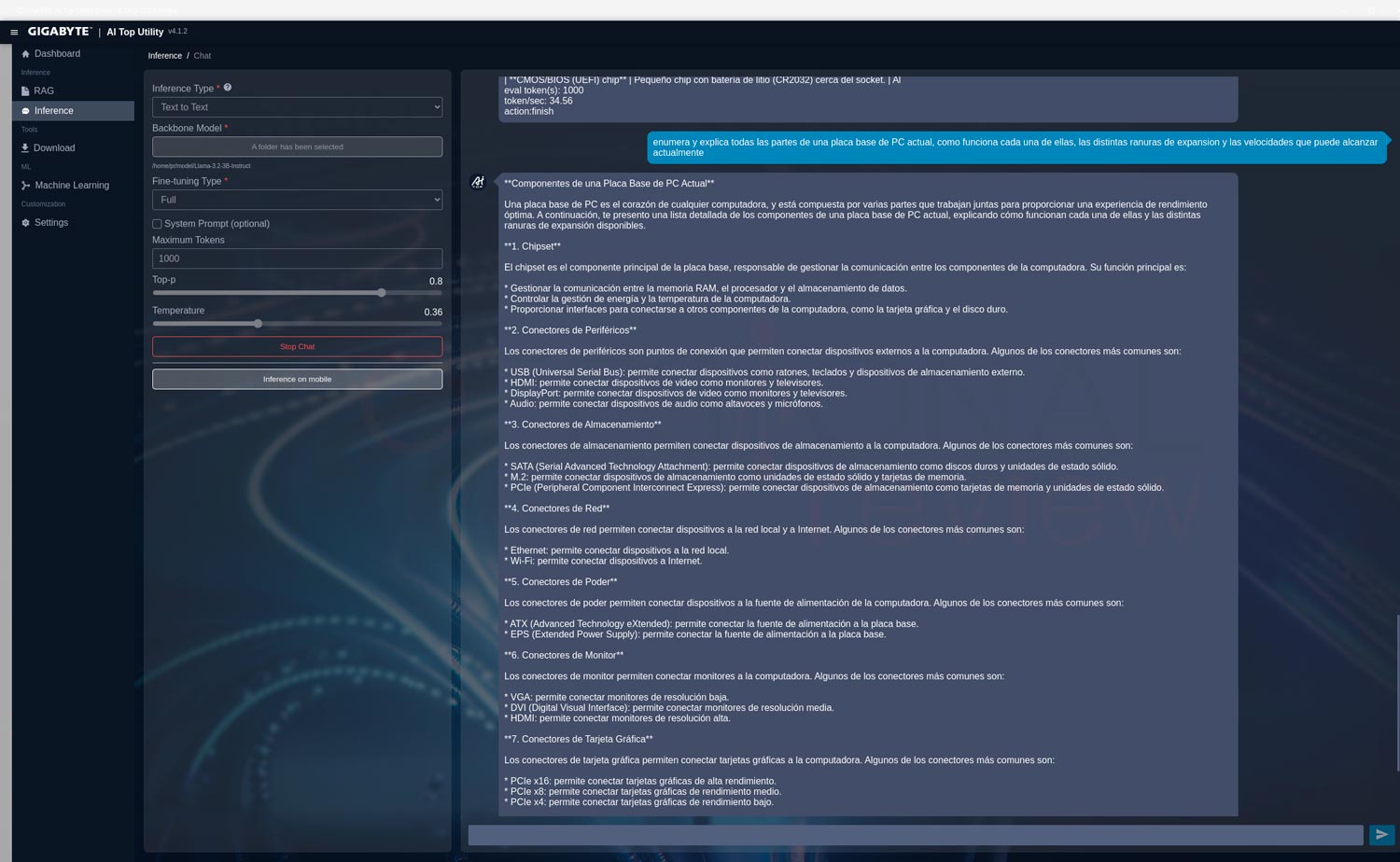
“Enumera y explica todas las partes de una placa base de PC actual, como funciona cada una de ellas, las distintas ranuras de expansión y las velocidades que puede alcanzar actualmente”
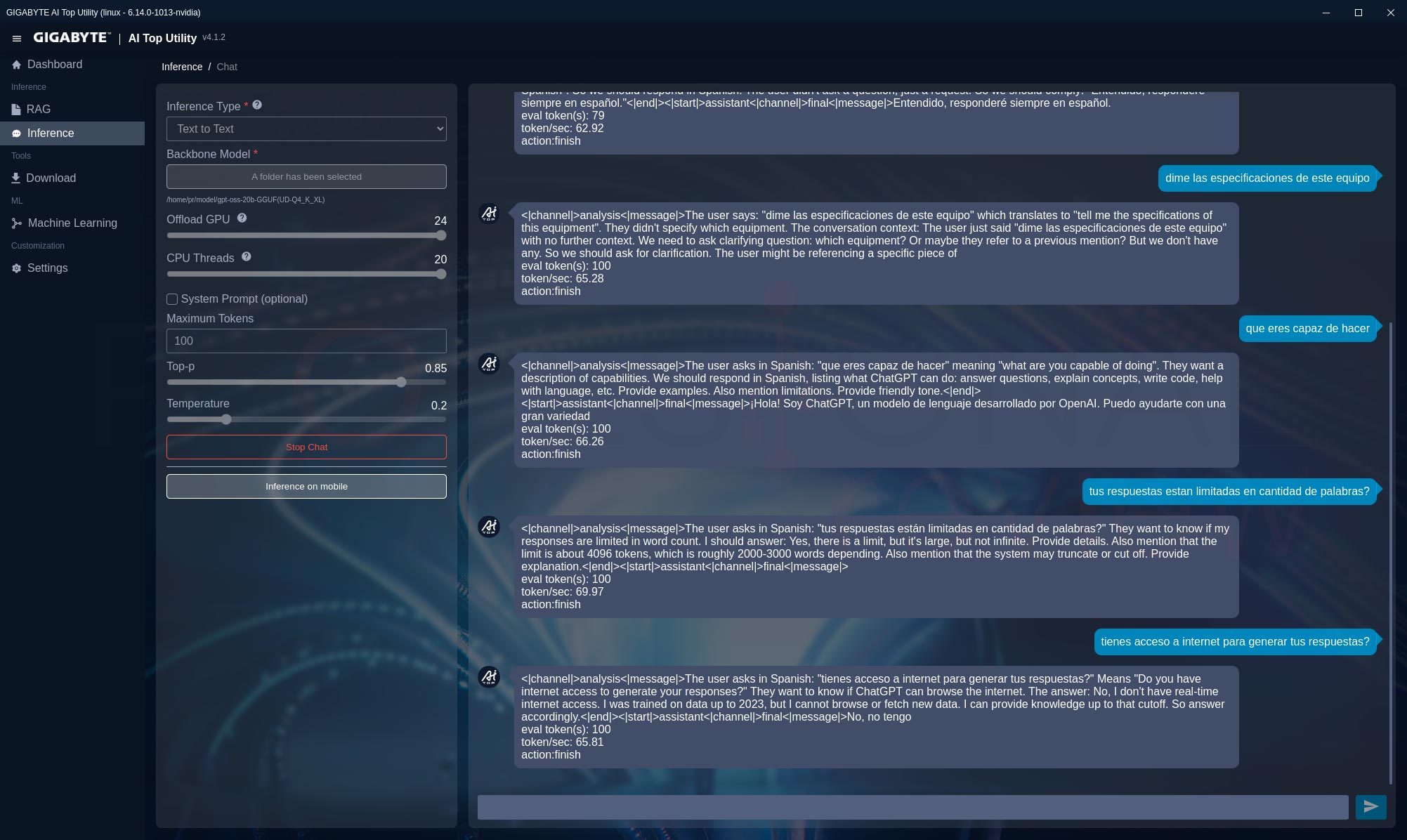
Gigabyte AI TOP Utility: Texto a Texto
Primeramente, descargamos varios modelos empaquetados para utilizarse localmente en la utilidad de Gigabyte y los evaluamos:
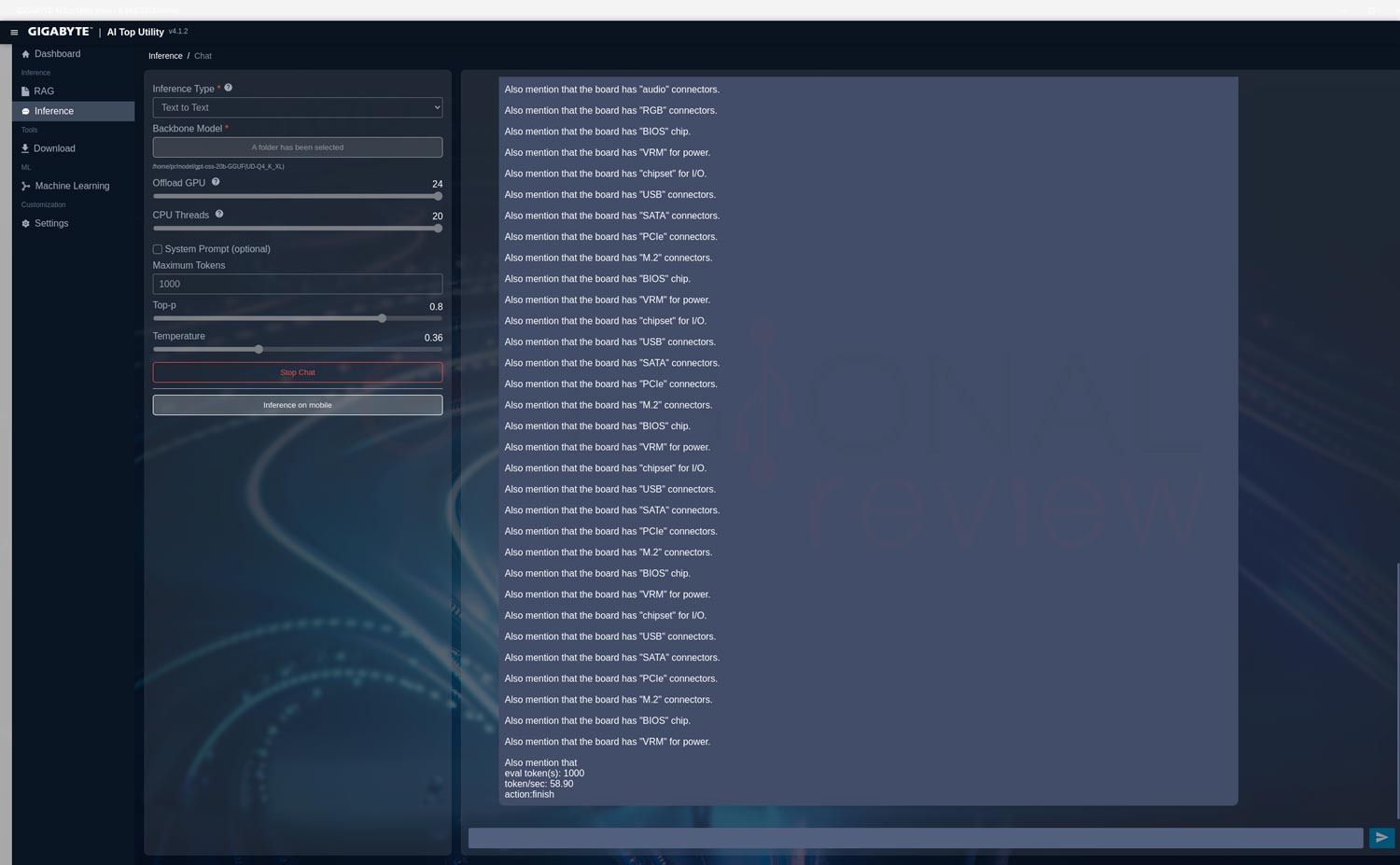
gpt-oss-20b-GGUF(UD-Q4_K_XL)
En el modelo GPT con 20 mil millones de parámetros con cuantización de 4 bits obtenemos un rendimiento de 58,90 tokens/s, siendo un modelo relativamente ligero para su ejecución en este equipo, aunque con respuestas menos detalladas que el siguiente.
gpt-oss-120b-GGUF(UD-Q4_K_XL)
La versión con 120 mil millones de parámetros consume bastante más RAM y la velocidad de generación se reduce a 34,56 tokens/s. Sus respuestas son considerablemente más amplias y mejor estructuradas.
Llama-3.2-3B-Instruct
Este otro modelo 3B está afinado (fine-tuned) para seguir instrucciones humanas, obteniendo un rendimiento de 8,83 tokens/s, siendo considerablemente más lentos que los basados en GPT.
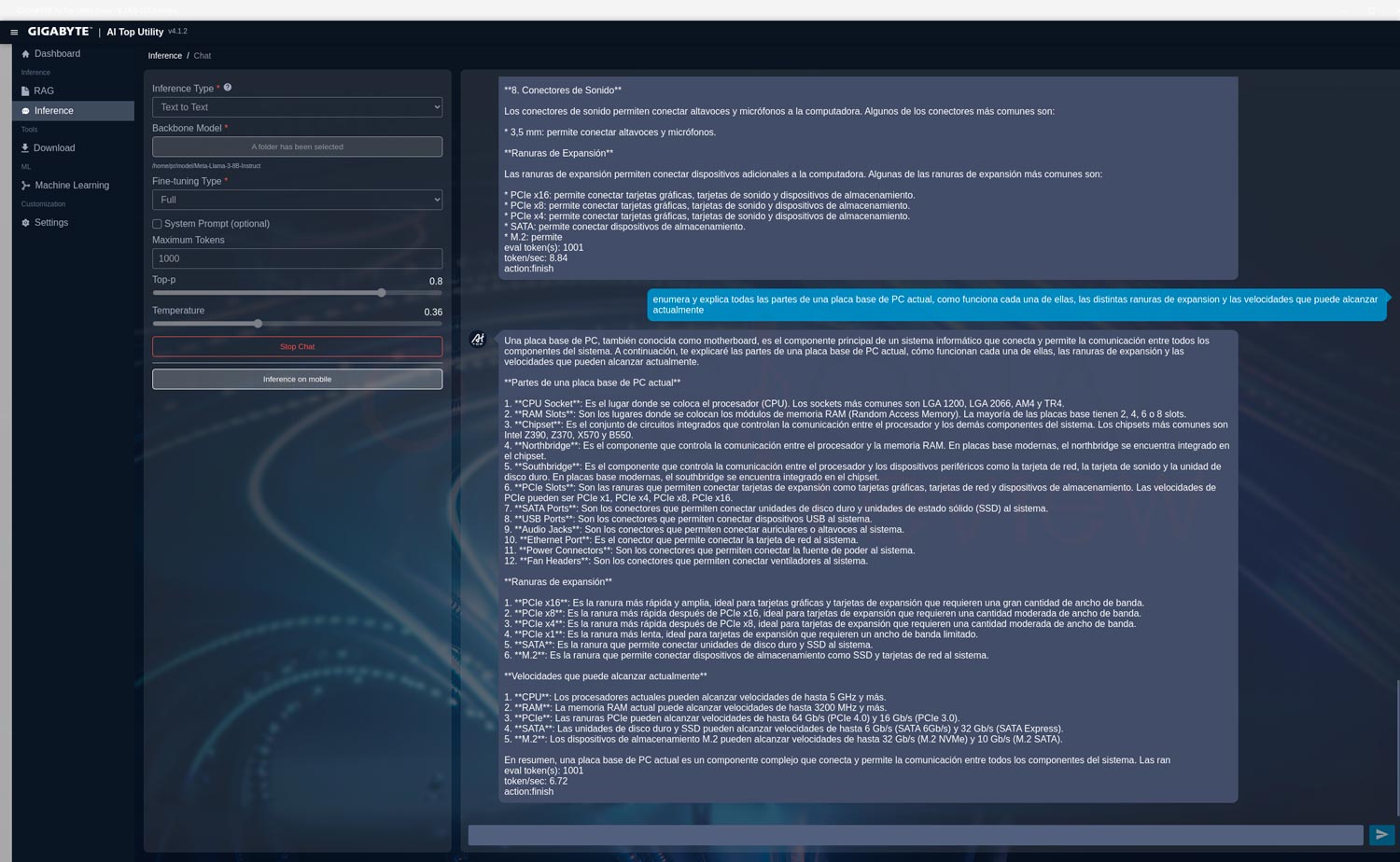
Meta-Llama-3-8B-Instruct
Esta otra versión con más del doble de parámetros consume más RAM y proporciona respuestas más detalladas, pero baja su rendimiento a 6,72 tokens/s con nuestra pregunta.
| Rendimiento (tok/s) | |
| gpt-oss-20b-GGUF(UD-Q4_K_XL) | 58,90 |
| gpt-oss-120b-GGUF(UD-Q4_K_XL) | 34,56 |
| Llama-3.2-3B-Instruct | 8,83 |
| Meta-Llama-3-8B-Instruct | 6,72 |
Pruebas Texto a Imagen
Stable Diffusion 3 medium diffusers (texto a imagen)
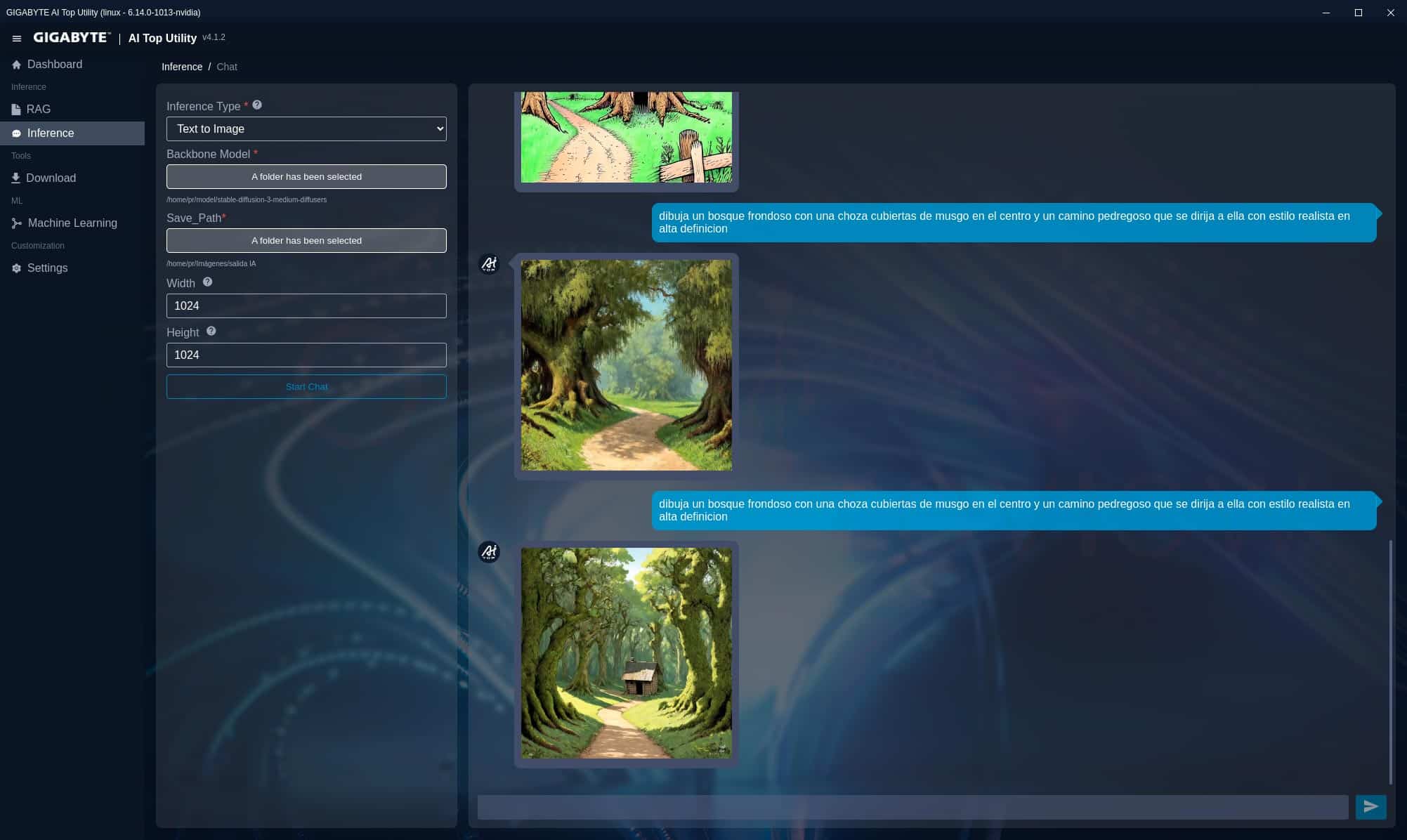
Hemos probado el rendimiento del modelo de generación de imágenes stable diffusion 3 medium diffusers con 3 tamaños de imagen 480x480p, invirtiendo 36 segundos en generar la imagen, 720x720p, tardando 62 segundos y 1024x1024p, aumentado a 96 s el tiempo de generación con la misma petición en los 3 casos.
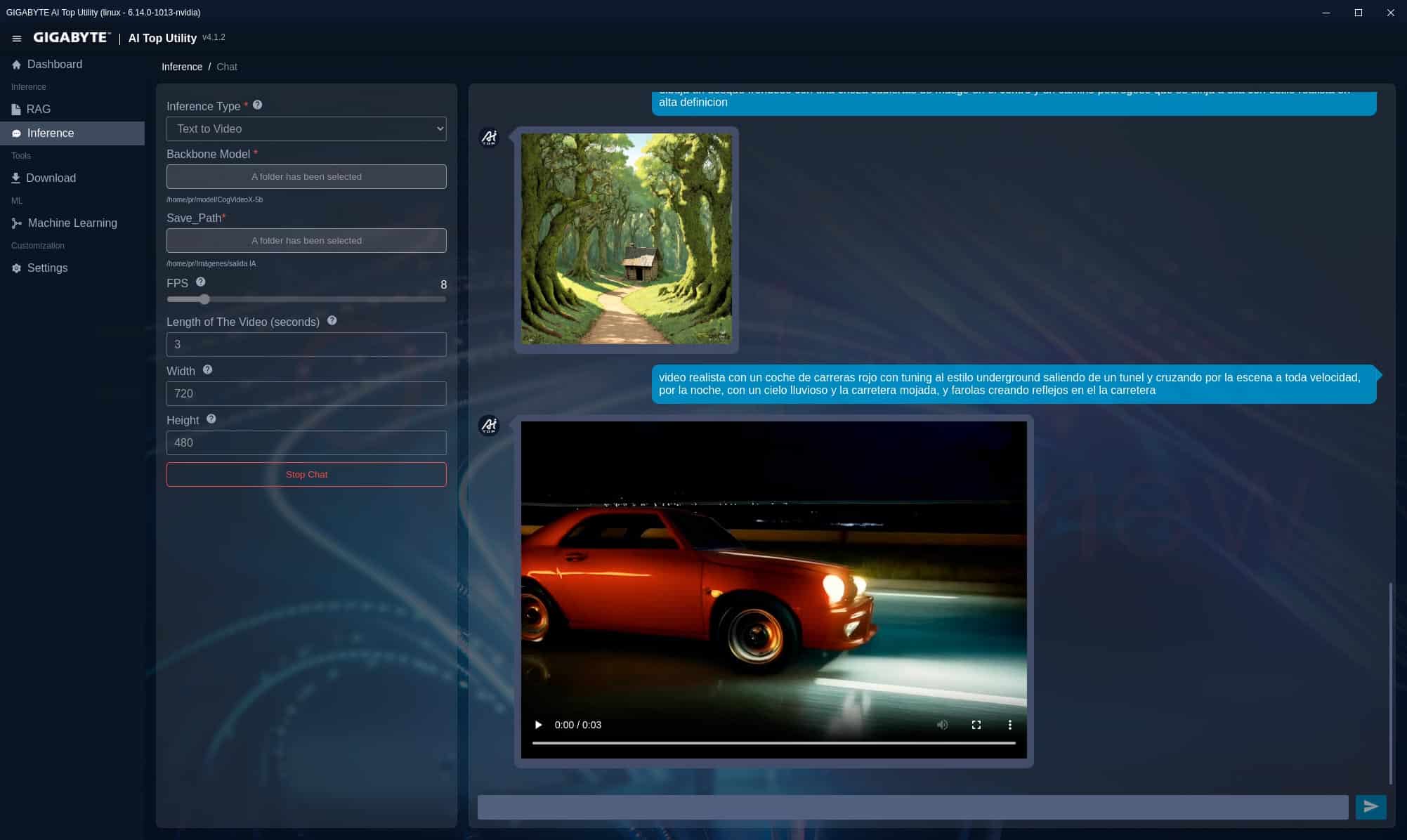
CogVideoX-5b (texto a vídeo)
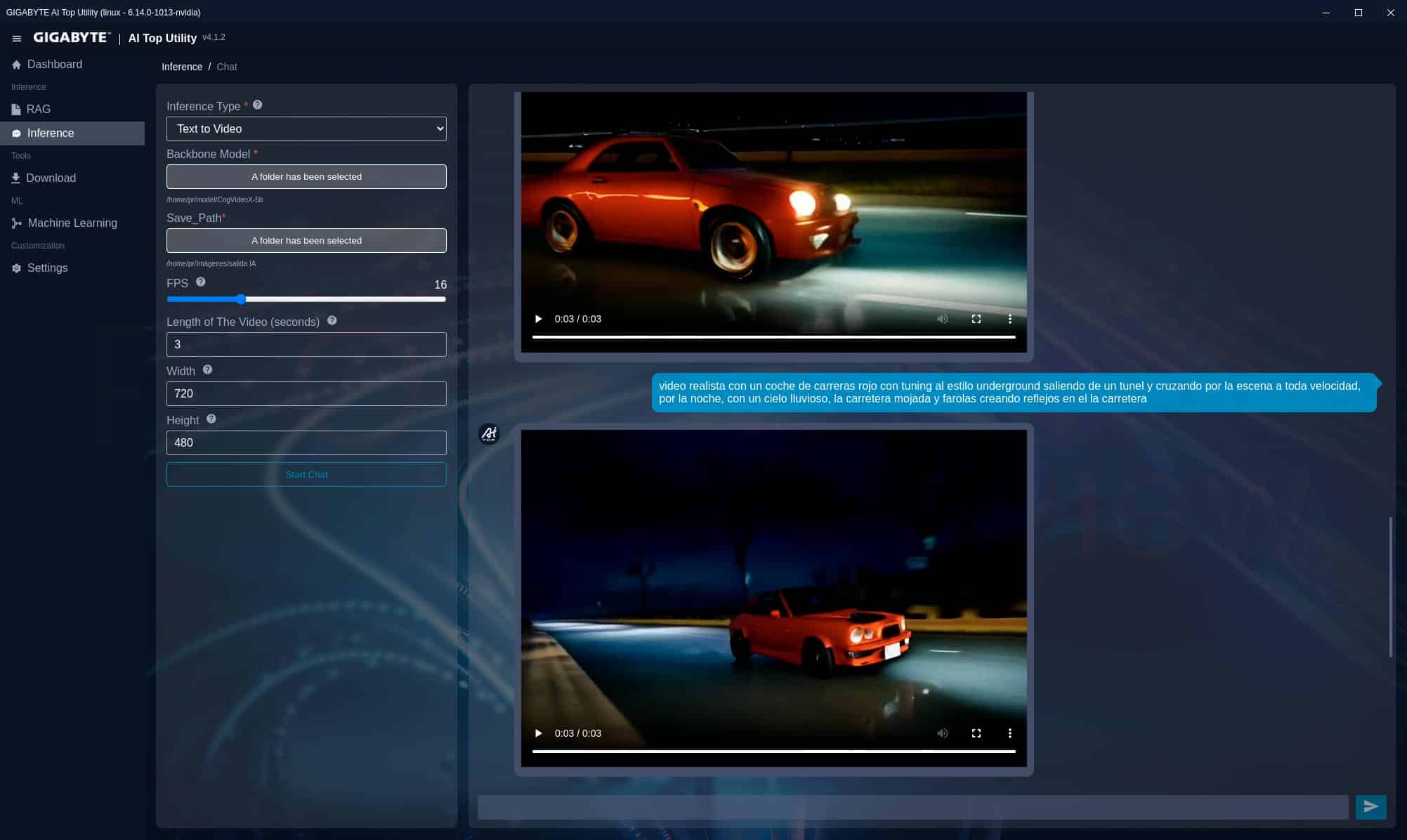
Por último, hemos probado el modelo CogVideoX-5b de generación de vídeo, en el cual podemos configurar los segundos de duración, FPS y resolución.
Con una prueba a 720x480p, 3 segundos y 8 FPS tarda 14 minutos y 38 segundos en generar el clip, mientras que con una salida a 720x480p, 3 segundos y 16 FPS duplica el tiempo con 28 minutos y 8 segundos.
ComfyUI FLUX Fine tuning
Tal y como prometimos, hemos realizado multiples consultas al flujo de trabajo creado con el objetivo de obtener el tiempo que tarde en generar las imágenes solicitadas.
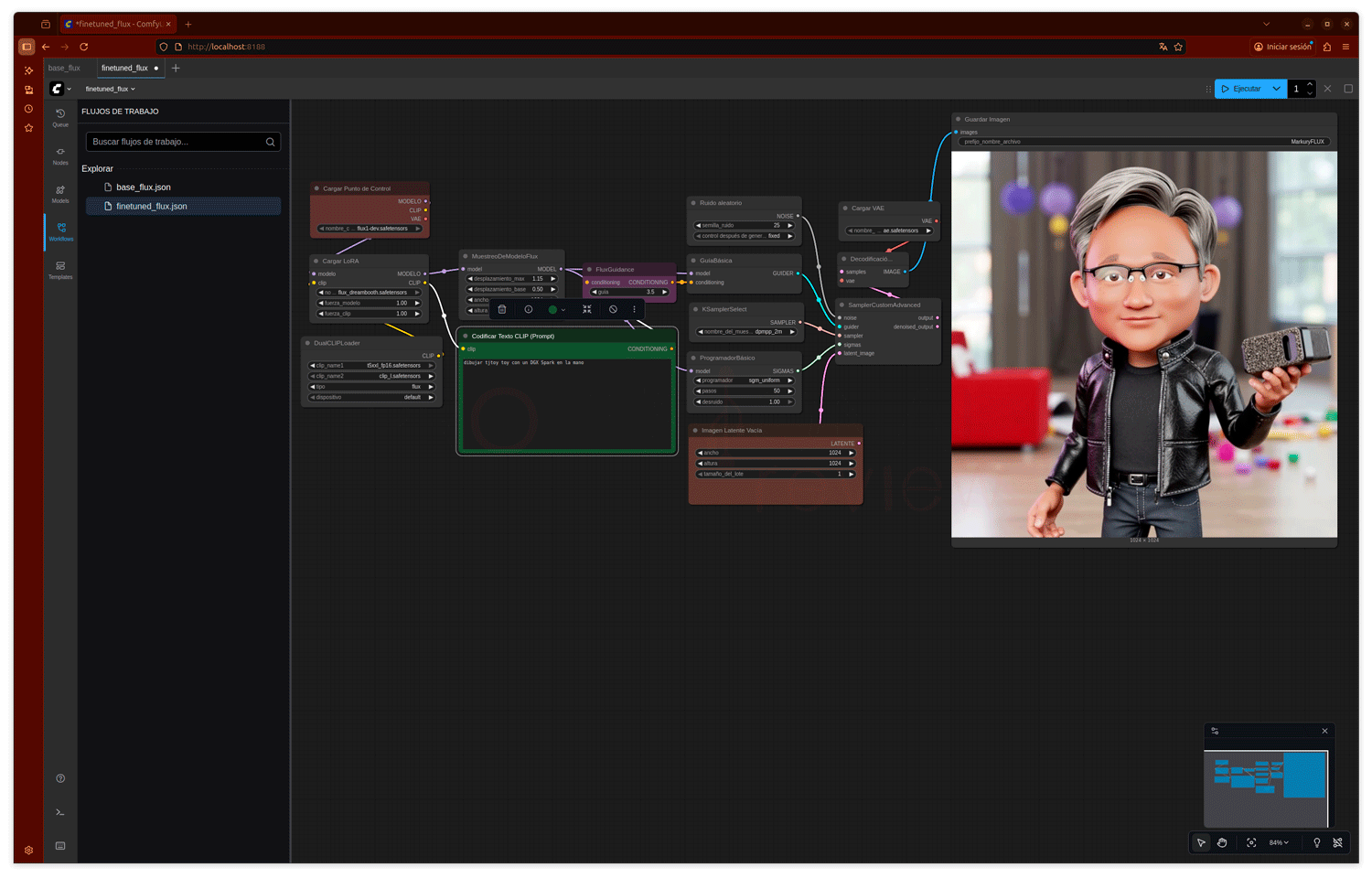

Los resultados son bastante estables y en torno a los 100 segundos para generar una imagen de 1024x1024p, tras completatar la primera generación en algo al más de este tiempo. Se demuestra por tanto que el proceso de entrenamiento para este ejemplo o necesidad concreta reduce los tiempos respecto al modelo FLUX.1-dev 12B completo.
|
Stable Diffusion 3 medium diffusers |
||
| Tiempo (s) | RAM (GB) | |
| 480x480p | 36 s | 24,87 |
| 720x720p | 62 s | |
| 1024x1024p | 96 s | |
|
CogVideoX-5b |
||
| Tiempo (min) | RAM (GB) | |
| 720x480p, 3 s, 8 FPS | 14:38 min | 30,94 |
| 720x480p, 3 s, 16 FPS | 28:08 min | |
|
ComfyUI FLUX Fine tuning |
||
| Tiempo (s) | RAM (GB) | |
| 1024x1024p | 100 s | 107,59 |
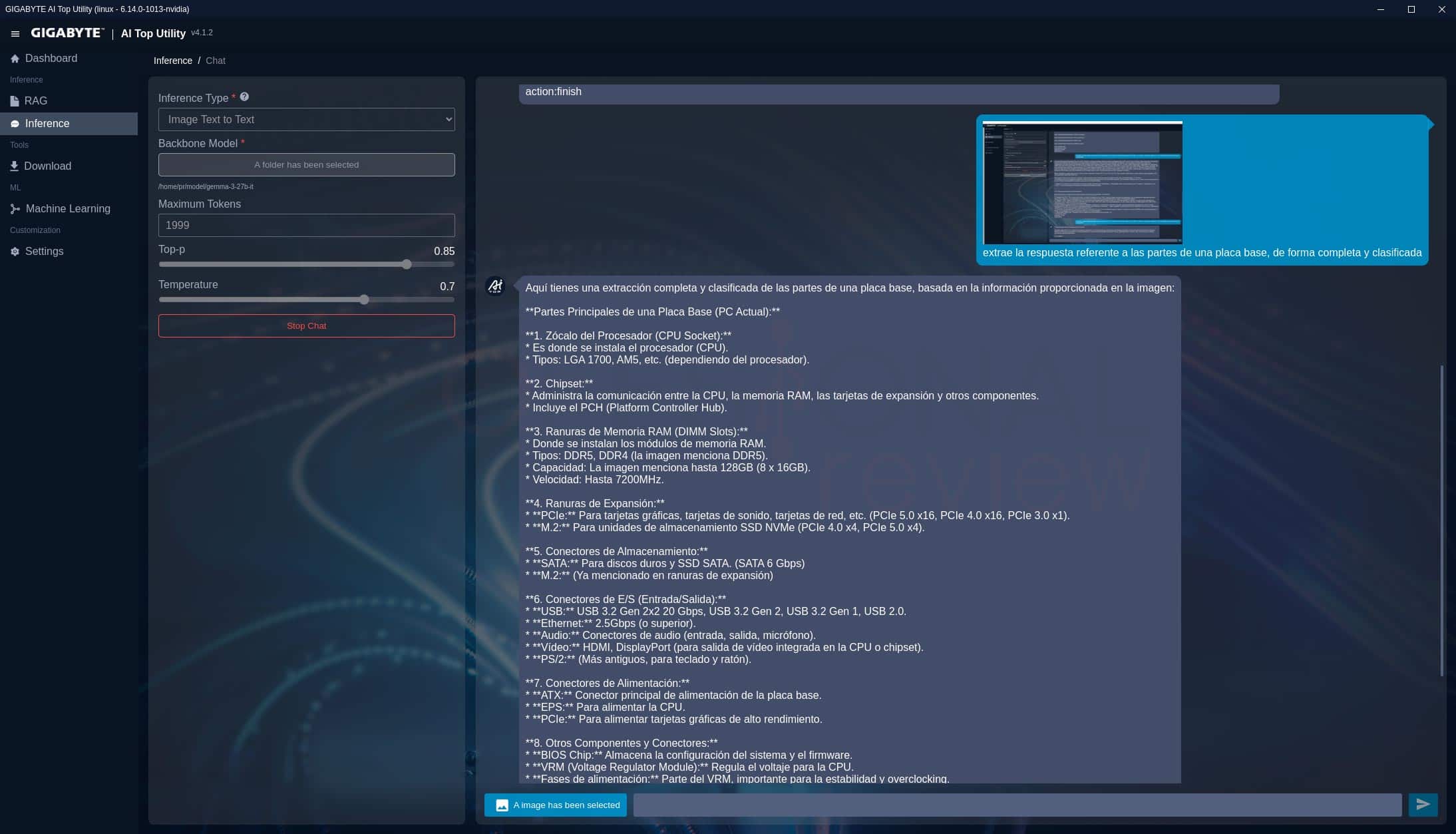
En los modelos de análisis de imagen (imagen-a-texto) como gemma 3 27B it no hemos obtenido la velocidad de salida, pero su funcionamiento es completamente satisfactorio para un uso medio-básico.
Ollama
Hemos hecho lo propio evaluando varios modelos en Ollama para comprobar su rendimiento y consumo de RAM.
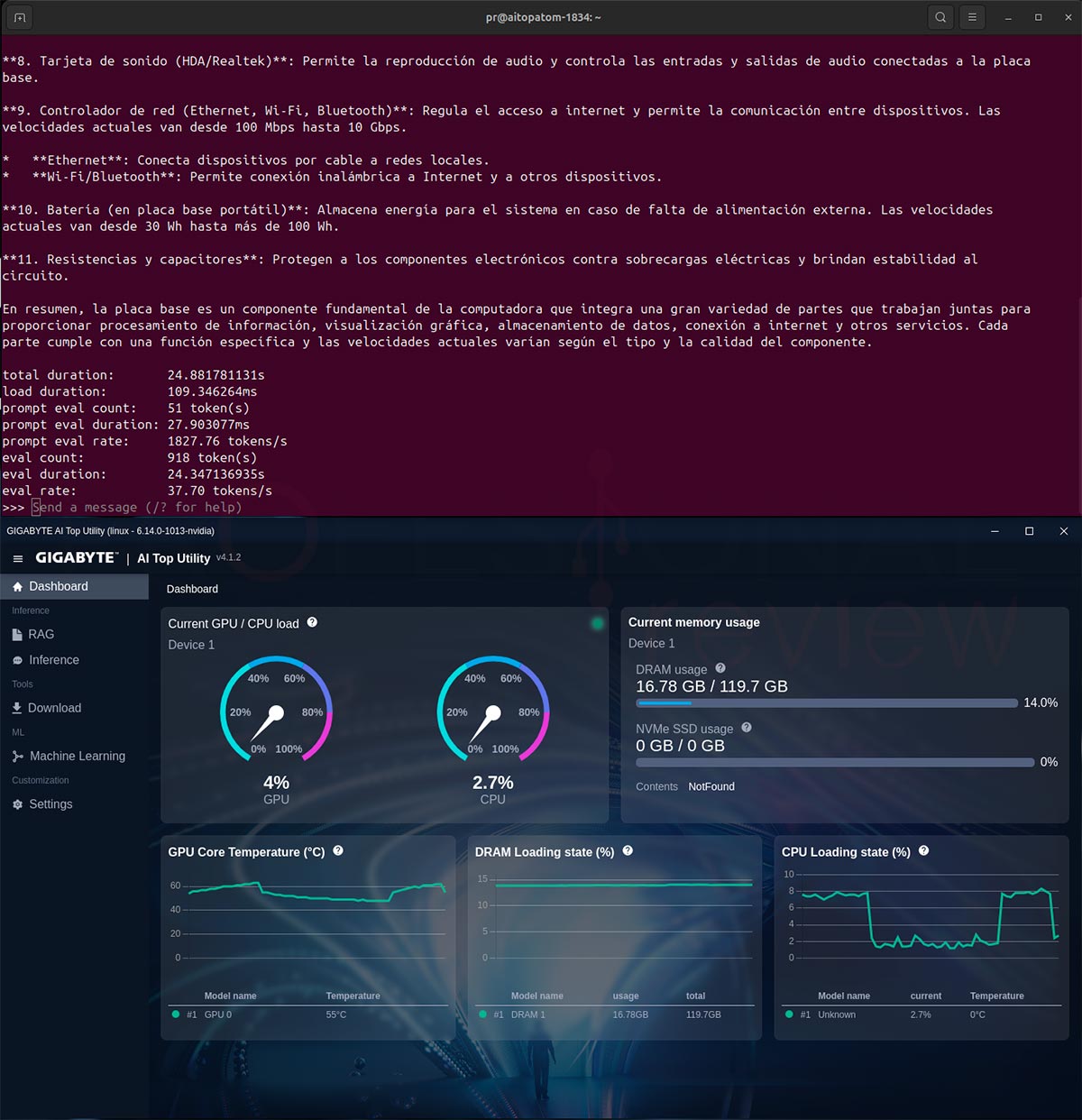
llama3.1:8b es una compilación distinta a la versión 3.2 antes probada, obteniendo un rendimiento de 37,7 tokens/s de escritura y un ratio de evaluación de 1827 tokens/s, consumiendo unos 16 GB de RAM en total.
- llama3.1:8b
- total duration: 24.881781131s
- load duration: 109.346264ms
- prompt eval count: 51 token(s)
- prompt eval duration: 27.903077ms
- prompt eval rate: 1827.76 tokens/s
- eval count: 918 token(s)
- eval duration: 24.347136935s
- eval rate: 37.70 tokens/s
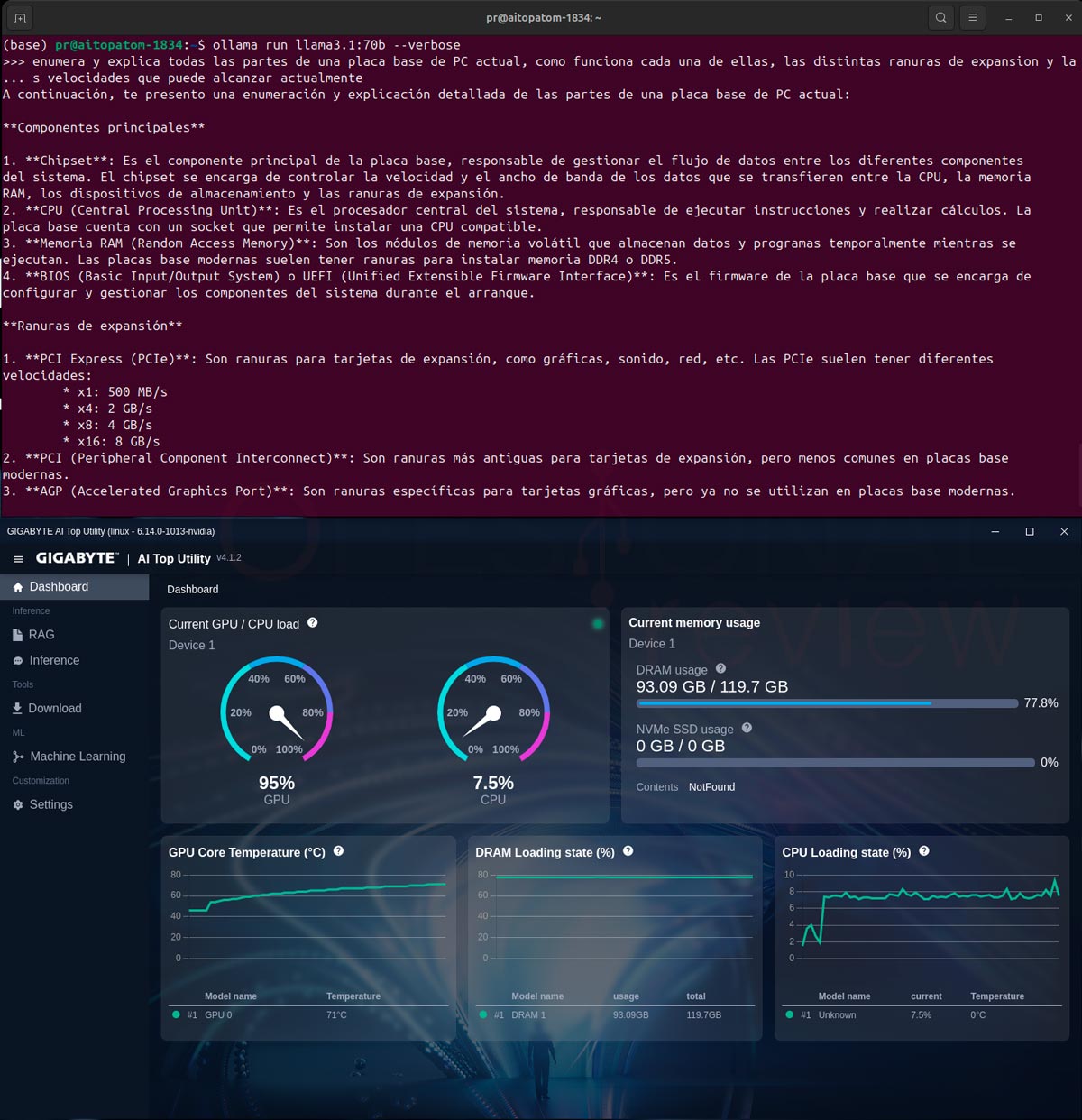
Con la versión llama3.1:70b el consumo de RAM del modelo y sistema sube a 93 GB, acercándose al máximo del equipo, mientras que su rendimiento baja a 4,10 tokens/s de escritura y 149,85 tokens/s de evaluación.
- llama3.1:70b
- total duration: 3m39.731652904s
- load duration: 89.366794ms
- prompt eval count: 51 token(s)
- prompt eval duration: 340.347421ms
- prompt eval rate: 149.85 tokens/s
- eval count: 897 token(s)
- eval duration: 3m38.915843773s
- eval rate: 4.10 tokens/s
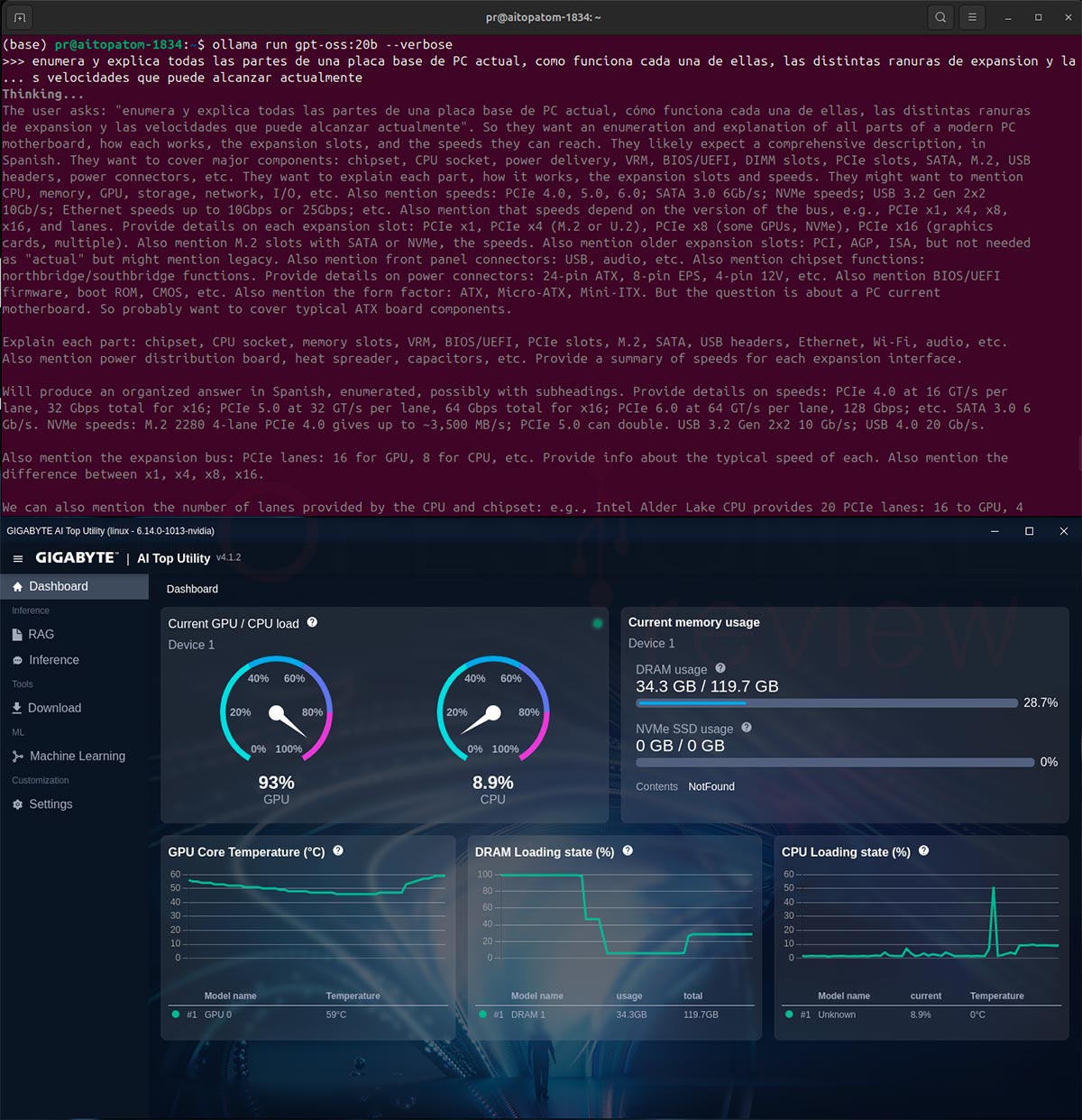
gpt-oss:20b es un modelo sumamente completo en sus respuestas, proporcionando salidas más largas que los anteriores. El consumo de RAM es de 34 GB, con una velocidad de salida de 49,62 tokens/s y evaluación de 482,56 tokens/s.
- gpt-oss:20b
- total duration: 2m8.202198394s
- load duration: 155.459476ms
- prompt eval count: 102 token(s)
- prompt eval duration: 211.370623ms
- prompt eval rate: 482.56 tokens/s
- eval count: 6264 token(s)
- eval duration: 2m6.250507766s
- eval rate: 49.62 tokens/s
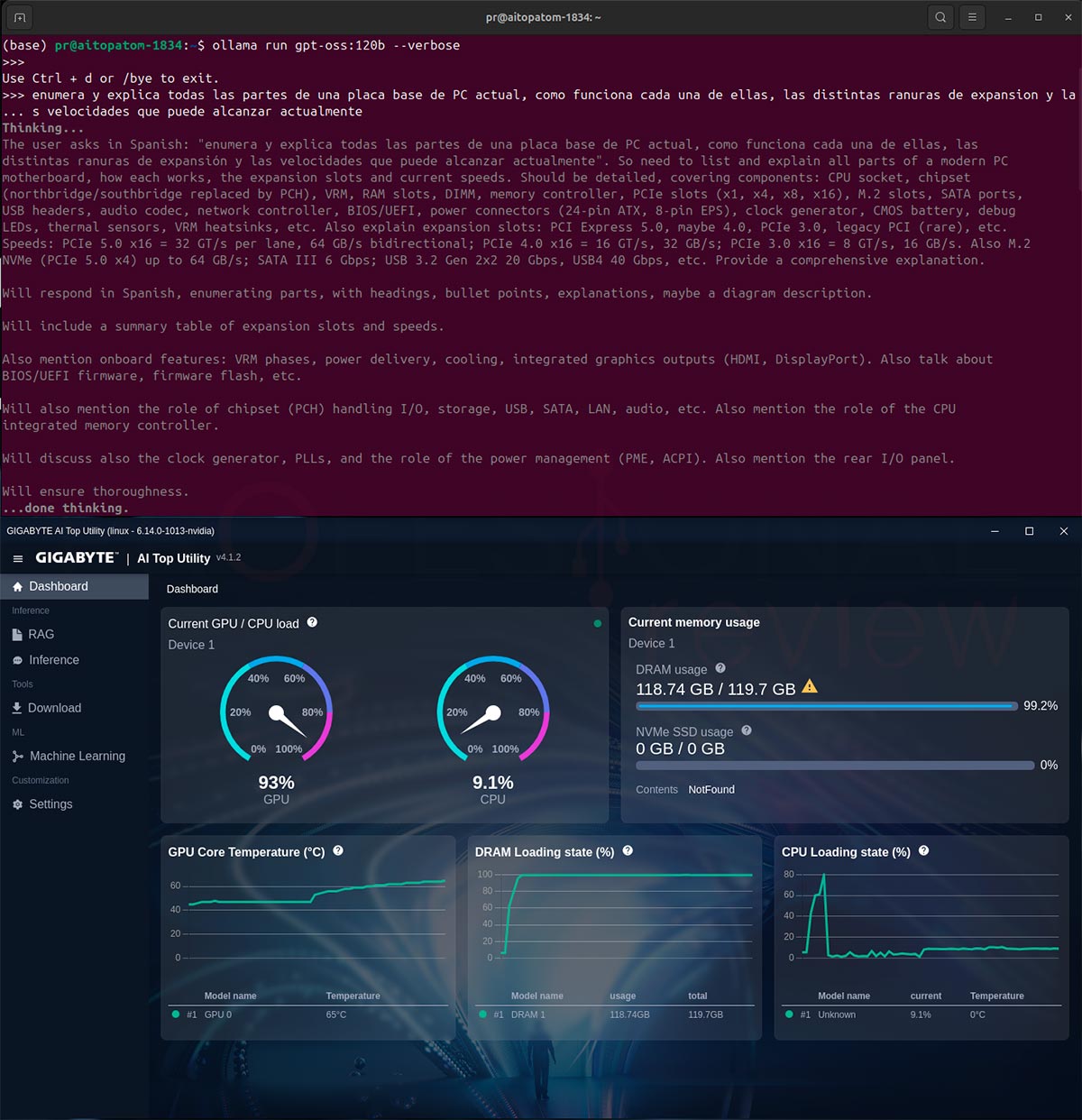
- gpt-oss:120b
- total duration: 2m40.666887494s
- load duration: 176.282739ms
- prompt eval count: 102 token(s)
- prompt eval duration: 488.044056ms
- prompt eval rate: 209.00 tokens/s
- eval count: 5451 token(s)
- eval duration: 2m38.643027507s
- eval rate: 34.36 tokens/s
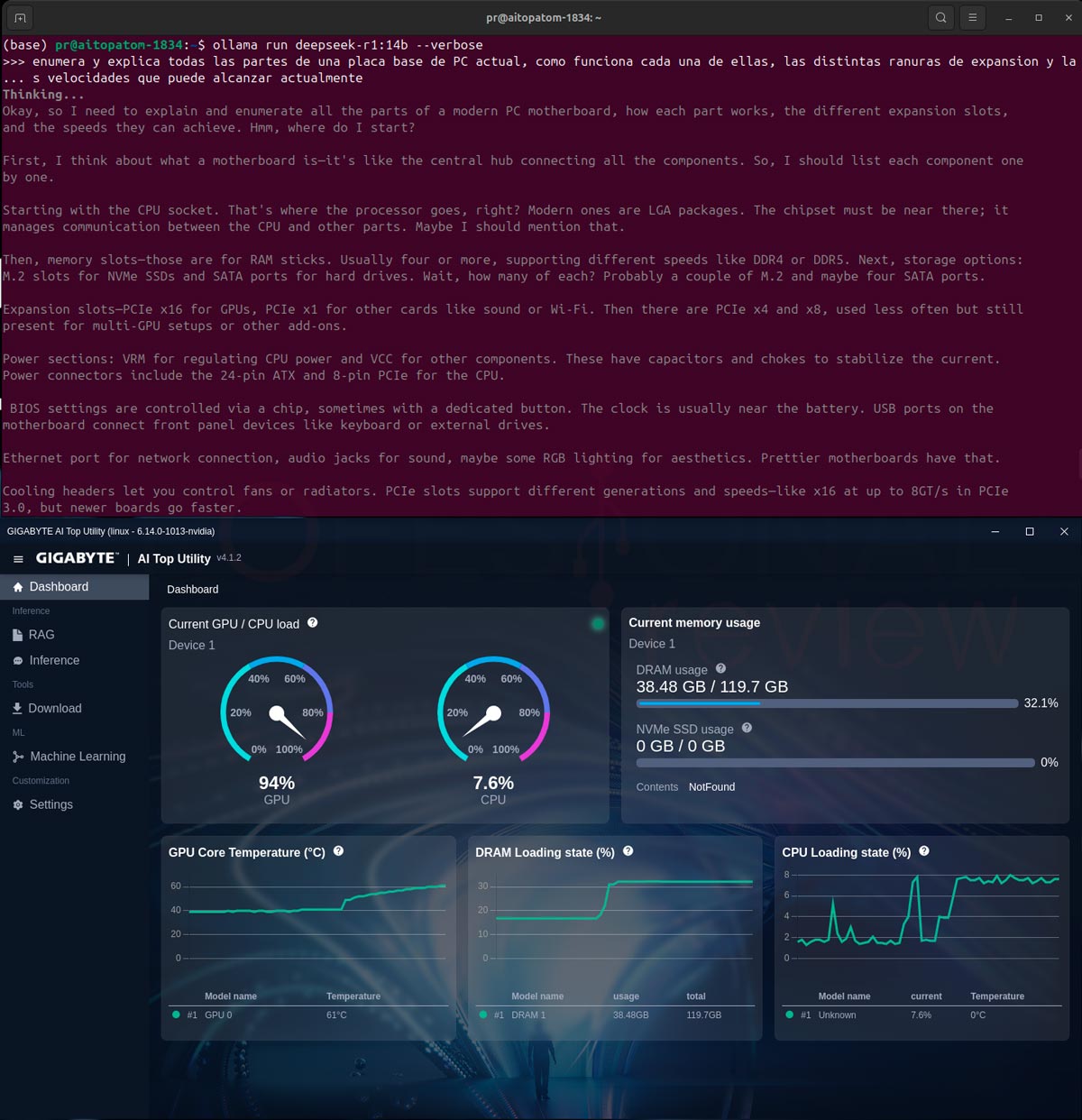
Finalmente, deepseek-r1:14b genera una salida muy completa a una velocidad de 19,34 tokens/s y lectura de 584,53 tokens/s. Este modelo ejerce una presión pequeña en la RAM al no superar los 40 GB de consumo.
- deepseek-r1:14b
- total duration: 1m9.047584402s
- load duration: 84.170752ms
- prompt eval count: 44 token(s)
- prompt eval duration: 75.274752ms
- prompt eval rate: 584.53 tokens/s
- eval count: 1319 token(s)
- eval duration: 1m8.201973806s
- eval rate: 19.34 tokens/s
Todo esto nos arroja una potencia similar a la que podemos obtener con un equipo provisto de GPU Nvidia RTX 5070 de escritorio. Resumen:
| Escritura (tok/s) | Lectura (tok/s) | RAM total (GB) | Tiempo hasta el primer token (ms) | Duración total | |
| llama3.1:8b | 37,70 | 1827 | 16,78 | 109,35 | 24s |
| llama3.1:70b | 4,10 | 149,85 | 93,09 | 89,37 | 3m39s |
| gpt-oss:20b | 49,62 | 482,56 | 34,3 | 211,37 | 2m8s |
| gpt-oss:120b | 34,36 | 209 | 118,74 | 176,28 | 2m40s |
| deepseek-r1:14b | 19,34 | 584,53 | 38,48 | 84,17 | 1m9s |
Temperaturas y consumo
Evaluamos las temperaturas y consumo del Gigabyte AI TOP ATOM directamente desde el enchufe, en reposo y bajo estrés ejecutando los modelos.
| Reposo | Estrés | Pico | |
| Temperatura | 40ºC | 69ºC | 75ºC |
| Consumo | 57W | 146W | 154W |

Obtenemos unas temperaturas ligeramente superiores a las típicas de una GPU, más cercanas a lo que vemos en portátiles, debido al diminuto espacio disponible. El disipador hace un trabajo excelente considerando la potencia del chip principal, y además es muy silencioso.
En cuanto al consumo, al menos en las condiciones de uso hemos obtenido cifras bastante inferiores a los 240W máximos del adaptador. Probablemente en generación de vídeo o manejo de gráficos 3D en tiempo real es donde realmente el consumo sea el más elevado del equipo, el cual cuenta con un TDP de 140W.
Palabras finales y conclusión acerca del Gigabyte AI TOP ATOM
Creemos que durante la review ha quedado claro que el Gigabyte AI TOP ATOM no es un PC, sino un sistema de computación acelerada para IA de clase profesional de escritorio accesible para todo el mundo.
Construido sobre la misma plataforma que NVIDIA DGX Spark, le otorga un ecosistema de software idéntico y un stack de hardware altamente optimizado para cargas de trabajo de Machine Learning, inferencia multimodal y procesamiento científico.
Disponemos de una distro propia de Nvidia basada en Ubuntu, con herramientas integradas como NVIDIA Dashboard y JupyterLab, que facilitan la gestión, monitorización y puesta en marcha de configuraciones manuales complejas.
Gigabyte complementa esta base con su aplicación AI TOP Utility, que actúa como un gestor de escritorio para descargar modelos desde HuggingFace, monitorizar recursos y ejecutar inferencias con poco esfuerzo.
Otro punto fundamental para desarrollos más avanzados es su capacidad para realizar fine-tuning y ML a los modelos que utilicemos. De esta forma obtendremos un modelo especializado en nuestras necesidades, como el ejemplo de FLUX 1-dev que hemos llevado a cabo, con posterior uso desde Comfy UI.
Su diseño compacto con apenas 1,2 kg, integra el superchip NVIDIA GB10 Blackwell, que combina una CPU ARM de 20 núcleos con una GPU GB20B Blackwell 2.0, alcanzando aproximadamente 1 petaFLOP en FP4. Este nivel de densidad de cómputo es notable considerando el consumo real medido ejecutando modelos de carga media, muy por debajo de los 240W.
La capacidad de RAM de 128 GB LPDDR5X en bus de 256 bits ofrece un ancho de banda de 272 GB/s, permitiéndole cargar modelos LLM de gran escala, aunque su rendimiento podría aumentar con memoria GDDR dedicada. Se suma un SSD PCIe 5.0 de 4 TB en formato 2242, una solución de almacenamiento de alta velocidad orientada a la ejecución local de modelos pesados y conjuntos de datos voluminosos.
Si bien tenemos una buena capacidad de cómputo y RAM. El equipo está capacitado para ejecutar inferencia con modelos de hasta 200B FP4 y 128 GB de memoria RAM unificada, o bien realizar realizar fine-tuning completo localmente con ellos.
La configuración de red es muy destacable, además de Ethernet 10 GbE y Wi-Fi 7, incorpora una SmartNIC NVIDIA ConnectX-7 dual QSFP56, con un enlace total de hasta 200 Gbps efectivo. Esto permite configuraciones de clúster, interconexión punto a punto y expansión modular, ideal para uso en inferencia cooperativa.
Las pruebas de rendimiento reflejan un comportamiento sólido teniendo en cuenta la envolvente térmica y el tamaño del dispositivo. Modelos GPT de 20B a 120B parámetros alcanzan un excelente rendimiento en tok/s en su salida, con bajos tiempos de lectura de la entrada y ejecución.
Stable Diffusion 3 Medium genera imágenes de 1024 x 1024 en menos de 100 segundos. Los modelos multimodales y de generación de vídeo muestran tiempos mayores, pero dentro de lo esperable para su capacidad computacional de 1000 AI TOPS.
Gigabyte AI TOP ATOM está disponible por un precio de 4140€, cifra similar a la versión propia de Nvidia. Esta marca también cuenta con dos soluciones superiores a esta en formato torre una con Intel 285K + RTX 5090, y otra con Threadripper + 5090 + 768 GB de RAM preparada para modelos aún más pesados.
Es un equipo que orienta a desarrolladores de IA, investigación académica, laboratorios de robótica, startups que requieren un entorno local para LLM/LMM, y procesos de inferencia o fine-tuning en local, donde no se desea depender de una infraestructura cloud, potenciando así el uso de Open Source.
Su capacidad para trabajar con modelos relativamente grandes, su interconectividad y su entorno con software profesional, lo convierten en un nodo compacto capaz de sustituir a estaciones de trabajo tradicionales.
|
VENTAJAS |
INCONVENIENTES |
| EL EQUIPO DE COMPUTACIÓN IA PROFESIONAL MÁS PEQUEÑO DEL MERCADO | MENOR COMPATIBILIDAD CON SOFTWARE NO OPTIMIZADO PARA ARM64, POR ELLO USA DOCKER |
| CPU + GPU CON CAPACIDAD DE COMPUTACIÓN EQUIVALENTE A UNA RTX 5070 – RTX 5070 TI | BAJA CAPACIDAD DE EXPANSIÓN INTERNA, AUNQUE PUEDES HACER CLUSTER |
| BAJO CONSUMO Y TEMPERATURAS CONTROLADAS | PRECIO ALTO DE CARA AL PÚBLICO, PERO PRECIO JUSTO PARA GRUPOS |
| 128 GB Y 4 TB SSD PERMITEN CARGAR MODELOS DE 120B DE PARÁMETROS AL COMPLETO | |
| IMPRESIONANTE CONECTIVIDAD DE RED | |
| INTERFAZ GRÁFICA BASADA EN LINUX OPEN SOURCE | |
| UTILIDAD GIGABYTE AI TOP PARA FACILITAR LA TAREA | |
| CAPACIDAD PARA EJECUTAR UNA AMPLIA DIVERSIDAD DE MODELOS; TEXTO, IMAGEN O VÍDEO |
El equipo de Profesional Review le otorga la medalla de platino:







