
Las instrucciones AVX-512 desarrolladas por Intel están cogiendo cada vez más protagonismo, sobre todo para los campos de la inteligencia artificial y el aprendizaje profundos. Veremos en este artículo qué son, para qué sirven y los tipos que hay, entre otros.
Índice de contenidos
Qué son las instrucciones AVX-512

Las Advanced Vector Extension (AVX-512) desarrolladas por Intel son una evolución de las instrucciones AVX y AVX2. Estas instrucciones de nueva generación se han creado para mejorar en lo posible el rendimiento donde existe una gran carga de trabajo.
Estas instrucciones están ganando popularidad debido a que ofrecen un tamaño de registro acumulado de 512 bits, permitiendo realizar hasta 16 operaciones de 32 bits. Pero además estas ofrecen el doble de ancho de banda, número de registros y ancho de las unidades FMA (operaciones fusionadas de acumulación múltiple) con respecto a las instrucciones AVX2.
Intel de momento es el único que integra las instrucciones AVX-512 únicamente en sus procesadores, aunque su origen es bien distinto. Debemos tener en cuenta que según la generación del procesador Intel, puede soportar más o menos extensiones de instrucciones AVX-512.
Origen AVX-512
Durante años Intel ha tratado de dar el salto al mercado de las GPU, desarrollando sus propias soluciones sin éxito hasta hace muy poco tiempo. La vez que más cerca estuvieron fue en 2010, cuando estaban muy cerca de lanzar al mercado las gráficas Intel Larrabee. Parece ser que estas no eran muy potentes y el proyecto termino desembocando en los aceleradores de procesamiento Intel Xeon Phi, que tuvieron escaso éxito en el mercado.
Para las Intel Larrabee la compañía desarrollo el set de instrucciones AVX-512, una versión avanzada (y mejorada) de las instrucciones AVX2. Estas nuevas instrucciones permitían un registro acumulado de 512 bits, soportando operar con hasta 16 datos de 32 bits. Básicamente esto supone un ratio de operaciones por texel en 16:1 veces más que una GPU.
Tras la reconversión de Larrabee a las Xeon Phi x200 (Knight Landing) y el paso de sin pena ni gloría, as instrucciones AVX-512 se empezaron a integrar posteriormente en los procesadores de Intel. Todos los procesadores que soportan este set de instrucciones, cuentan con soporte para al menos la extensión AVX-512-F. Existen instrucciones que se van añadiendo en diferentes familias de procesadores.

Te recomendamos la lectura:
Para qué sirven las instrucciones AVX-512
La función de este tipo de instrucciones es indicarle al procesador como gestionar los flujos de datos que le llegan, según el tipo de dato. Permite por lo tanto que el procesador tenga una mayor capacidad de gestión y le permite identificar cuál es el mejor método y más eficiente de procesamiento para ofrecer el mejor rendimiento posible.
Este tipo de instrucciones permite la aceleración del rendimiento cuando se dan cargas de trabajo elevadas. Sobre todo son útiles para mejorar la aceleración de tareas como simulaciones científicas, análisis financiero, inteligencia artificial y aprendizaje profundo, modelado y análisis 3D, procesamiento de imágenes y audio/video, criptografía y compresión de datos.
Te recomendamos la lectura de los mejores procesadores del mercado
AVX-512 puede ofrecer además capacidad a los Data Centers a utilizar los recursos de almacenamiento disponibles de un modo más eficiente. Permite acelerar tareas como el cifrado, la compresión y descompresión de los datos, reduciendo a la mitad los tiempos con respecto a las instrucciones de generación anterior. Se consigue mediante la duplicación del número de bits en el registro, pasando de 256 bits a los 512 bits de estas nuevas instrucciones.
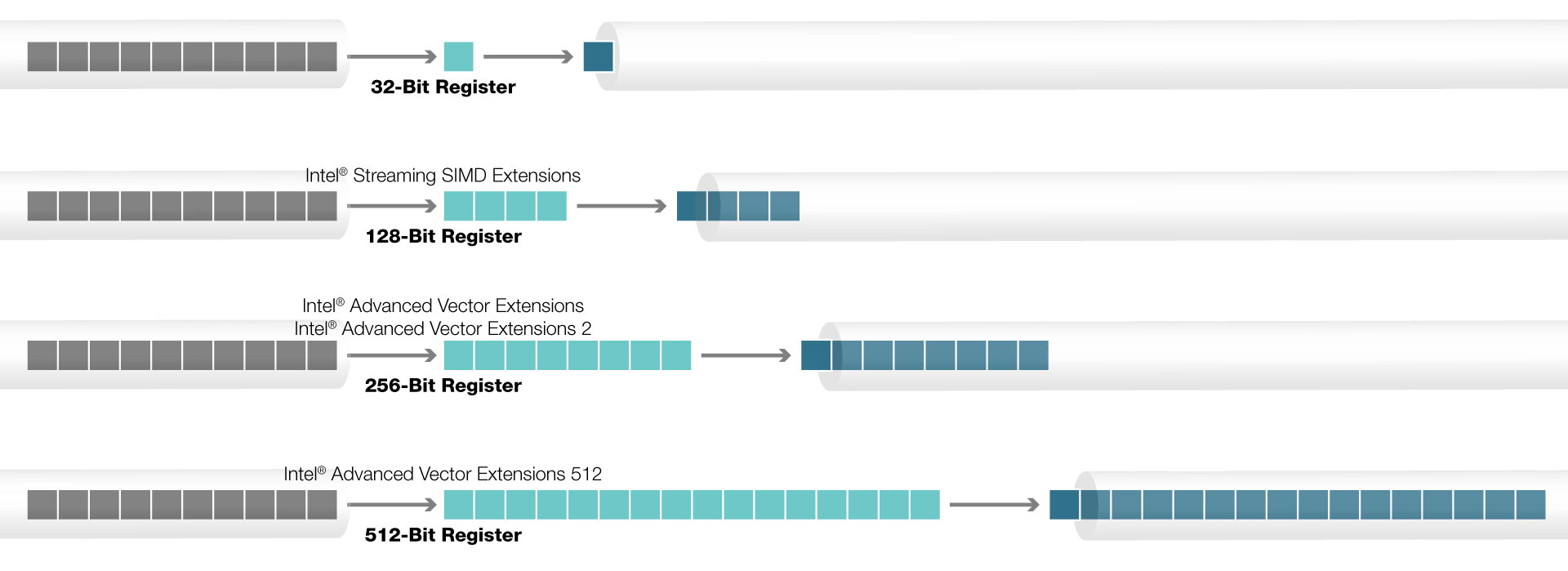
Tipos de instrucciones AVX-512
Vamos a ver ahora los tipos de instrucciones que se pueden encontrar en la actualidad y en que familias de procesadores se empiezan a integrar. No entraremos en detalles sobre que ofrecen o como funcionan este tipo de instrucciones, ya que puede ser algo bastante tedioso. Actualmente las extensiones existentes son:
- AVX-512-F (Foundation): Instrucciones de 32 bits y 64 bits con esquema de codificación EVEX que permite registros de 512 bits, mascaras de operación, transmisión de parámetros y redondeo integrado y control de excepciones. Primer set de instrucciones creado por Intel e introducidas en las Knight Landing y en los Xeon Skylake-EP/EX
- AVX-512-CD (Conflict Detection): Detección eficiente de conflictos para permitir la vectorización de más bucles. Introducidas en las Knight Landingy en los Skylake-X
- AVX-512-ER (Exponential and Reciprocal Instructions): Operaciones exponenciales y recíprocas diseñadas para ayudar a implementar las operaciones transcendentales. Introducidas en las Knight Landing
- AVX-512-PF (Prefetch Instructions): Nuevas capacidades de captación previa. Introducidas en las Knight Landing
- AVX-512-VL (Vector Length Extension): Amplía la mayoría de operaciones AVX-512 para que operen registros XMM (128 bits) e YMM (256 bits). Introducidas en los Skylake-X y Cannon Lake
- AVX-512-DQ (Doubleword and Quadword Instructions): Añade nuevas instrucciones de 32 bits y 64 bits. Introducidas en los Skylake-X y Cannon Lake
- AVX-512-BW (Byte and Word Instructions): Amplía las intrusiones AVX-512 para que soporte operaciones con enteros de 8 bits y 16 bits. Introducidas en los Skylake-X y Cannon Lake
- AVX-512-IFMA (Integer Fused Multiply Add): Suma de multiplicación fusionada de enteros con precisión de 52 bits. Introducidas en los Cannon Lake
- AVX-512-VBMI (Vector Byte Manipulation Instruction): Añade instrucciones de permutación de bytes vectoriales que no estaban presentes en AVX-512-BW. Introducidas en los Cannon Lake
- AVX-512-4VNNIW (Vector Neural Network Instructions Word variable precision): Instrucciones vectoriales para aprendizaje profundo, palabras mejoradas y precisión variable. Introducidas en los Kinghts Mill
- AVX-512-4FAMPS (Fused Multiply Accumulation Packed Single precision): Instrucciones para aprendizaje profundo, punto flotante y precisión simple. Introducidas en los Kinghts Mill
- AVX-512-VPOPCNTDQ (Vector population count instruction): Instrucciones de conteo de población vectorial. Introducidas en los Knights Mill e Ice Lake
- AVX-512-VNNI (Vector Neural Network Instructions): Instrucciones vectoriales para el aprendizaje profundo. Introducidas en Ice Lake
- AVX-512-VBMI2 (Vector Byte Manipulation Instructions 2): Carga, almacenamiento y concentración de bytes/palabras con desplazamiento. Introducidas en Ice Lake
- AVX-512-BITLAG (Bit Algorithms): Instrucciones de manipulación de bits de byte/palabra que expande a las instrucciones AVX-512-VPOPCNTDQ. Introducidas en Ice Lake
- AVX-512-VP2INTERSECT (Vector Pair Intersection to a Pair of Mask Registers): Instrucciones de par de registro de máscara. Introducidas en Tiger Lake
Modos SMID
Las instrucciones AVX-512 se han desarrollado para combinar las instrucciones AVX y AVX2 sin una penalización de rendimiento. Además en la extensión AVX-512-VL se añade un aumento en los registros XMM e YMM.
Adicionalmente las instrucciones SEE y AVX/AVX2 cuentan con versiones AVX-512-VL codificadas con prefijo EVEX, pero con nuevas funciones como opmask y registros adicionales. Estas instrucciones AVX-512-VL son sin mnemónicos, pero comparten espacio de nombres AVX, permitiendo distinguir versiones codificadas VEX y EVEX de una instrucción ambigua en el código fuente.
Seguro que te interesa echarle un vistazo a nuestro artículo sobre: ¿Qué es un procesador y como funciona?
En el archivo de registro SMID se incrementa de 256 bits a los 512 bits, y se amplía de 16 registros a los 32 registros ZMM0-ZMM31. Dichos registros se pueden direccionar como registros YMM de 256 bits desde extensiones AVX y en registros XMM de 128 bits desde extensiones SMID de transmisión y las instrucciones AVX y SEE heredadas se pueden extender para operar en los 16 registros adicionales (XMM16-XMM31 / YMM16-YMM31) cuando se usa EVEX de manera codificada.
Posible adopción por parte de AMD

La idea de AMD, al fabricar sus propias CPU y GPU, siempre ha sido la aceleración de aplicaciones de manera combinada. Esto hace que AMD no tenga mucho interés en la integración de las instrucciones AVX-512 en sus procesadores, en una primera instancia.
Sus GPU basadas en la arquitectura CDNA permiten en gran rendimiento en aplicaciones avanzadas. AMD apuesta más en una computación heterogénea, aunque muchos algoritmos están optimizados para el uso de GPU, esto hace que no termine de aprovechar bien las características de un sistema combinado de CPU-GPU.
Esto podría provocar que AMD finalmente termine integrando las instrucciones AVX-512 en sus procesadores. Se especula que los procesadores de arquitectura AMD Zen4 podrían dar soporte a este tipo de instrucciones AVX-512 con el fin de aprovechar mejor el potencial de los sistemas heterogéneos.
Linus Torvalds y AVX-512

Hace unos meses Linus Torvalds, creador de Linux, concedió una entrevista al medio Real World Tech y hablo sobre las instrucciones AVX-512. Parece que este tipo de instrucciones no gustan nada al padre del sistema operativo Linux, quien no ha dudado en cargar contra ellas y de paso contra Intel:
Espero que AVX512 tenga una muerte dolorosa, y que Intel comience a solucionar problemas reales en lugar de tratar de crear instrucciones mágicas para luego crear benchmarks en los que puedan verse bien.
Espero que Intel vuelva a lo básico: que sus procesos vuelvan a funcionar y se concentre más en el código regular que no es HPC o algún otro caso especial sin sentido.
(…) Porque absolutamente a nadie le importa fuera de los benchmarks.
Lo mismo ocurre en gran medida con AVX512 ahora, y en el futuro. Sí, puedes encontrar cosas en las que es importante. No, esas cosas no venden equipos en el panorama general.
Y AVX512 tiene desventajas reales. Prefiero que el presupuesto de transistores se use en otras cosas que son mucho más relevantes. Incluso si todavía son matemáticas de FP (en la GPU, en lugar de AVX512). O simplemente dame más núcleos (con un buen rendimiento de un solo hilo, pero sin basura como AVX512) como lo hizo AMD.
Quiero que mis límites de potencia se alcancen con un código regular de enteros, no con un virus como AVX512 que elimina la frecuencia máxima y quita núcleos (porque esas unidades de basura son inútiles y ocupan espacio).
Sí, sí, soy parcial. (…)
Palabras finales sobre AVX-512
Las instrucciones AVX-512 se caracterizan por estar directamente desarrolladas por Intel principalmente para la inteligencia artificial y el aprendizaje profundo. Estas instrucciones, nacidas de un diseño fallido, parece que están siendo bastante bien acogidas por parte de los desarrolladores.
Si bien el usuario medio no las utilizara y muy posiblemente no sabe ni que existan, sí que se podrían ver beneficiados por ellas. Estas instrucciones podrían mejorar la IA de los juegos y otras aplicaciones de uso cada vez más frecuente, como son las videollamadas.






