Las interconexiones 3D no son nuevas, aunque 3D V-Cache de AMD ha sido un éxito y buscamos alternativas.
SK hynix y AMD (ATI) fueron quienes crearon la memoria HBM allá por 2013, encabezados por Joe Macri (CTO de Raedon en AMD) y por el equipo de I+D de SK. Pensaron que GDDR no podría escalar más, si querían mejorar rendimiento/vatio sin ocupar mucho más espacio añadiendo más VRAM. Sí, HBM supone una interconexión 3D, así que puede ser uno de los pilares de 3D V-Cache.
Índice de contenidos
Última actualización el 2026-06-10
Debemos diferenciar un tecnologías de empaquetado 3D de un producto finalizado con interconexiones 3D.
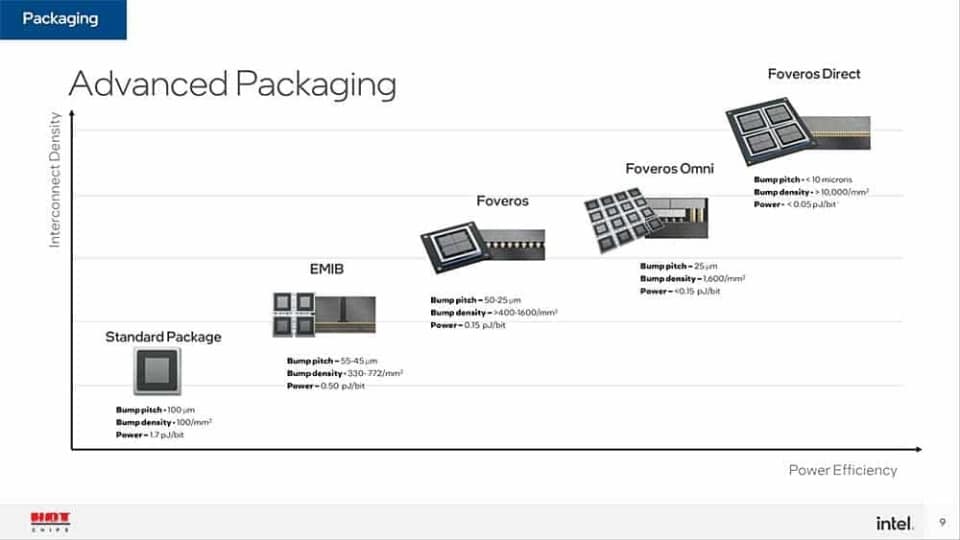
Empezando por las tecnologías de packaging 3D, encontramos a TSMC con su tecnología SoIC Hybrid Bonding y CoWos-S. Hybrid Bonding es la usada en 3D V-Cache, donde usan una unión híbrida sin bolas de soldadura donde las superficies se unen a nivel atómico.
CoWos-S integra un sistema a través de interconexiones de alta densidad y condensadores de zanja profunda utilizando interposers. Es ideal para soluciones de HBM, ya que CoWoS-S puede integrar u interposer de hasta 2700 mm², y para soluciones más grandes TSMC tiene CoWoS-L o R.
Intel tiene su enfoque rival con Foveros, una unión híbrida de cobre a cobre, como también con Foveros Omni, que permite apilar chips de distintos tamaños y nodos.
Foveros Omni es muy interesante y lo ha puesto en práctica en sus últimas generaciones de procesadores, como es el caso de Panther Lake donde el chip se distribuye por mosaicos. Esto le permite personalizar y escalar las soluciones según las necesidades del cliente. Hablamos de integración heterogénea, así que
Terminando con Samsung, ellos tienen X-Cube, una tecnología de packaging 3D donde apila verticalmente distintos chips a través de interposers (TSV) y la unión por microcontactos. Anunció esta novedad en agosto de 2020 con un chip FinFet, pero ya sabéis que la idea de Samsung es pasar a GAA. Lanzó esta tecnología para SRAM 3D a 7 nm.
Todos conocéis 3D V-Cache y los AMD Ryzen X3D, una tecnología que apila memoria caché L3 en los procesadores Ryzen para realizar más instrucciones y reducir la latencia = más rendimiento. Voy a contaros las alternativas directas que hay.
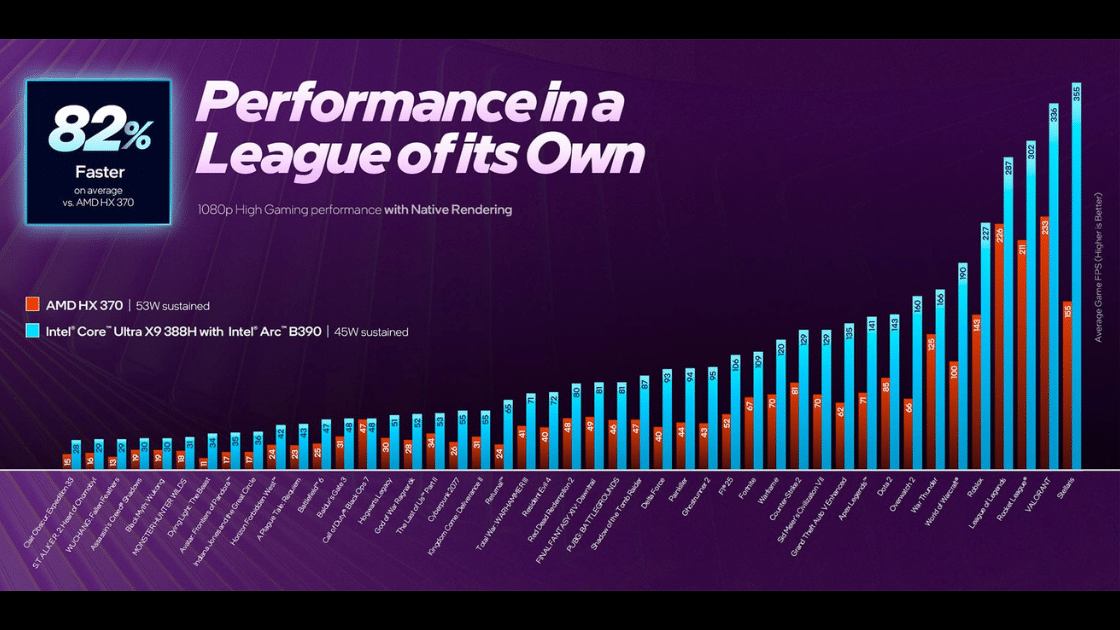
Sin embargo, hay alternativas 3D V-Cache, y voy a comenzar con los Intel Core Ultra Serie 3 (Panther Lake). Son fabricados con Foveros Direct, juntando los mosaicos del chip con una unión híbrida de cobre. Intel lo ha hecho así para que la iGPU esté al lado del Compute tile y Plataform Controller tile (I/O) con el fin de tener un acceso rápido a datos.
Buscan conseguir más rendimiento GPU para gaming y tareas profesionales, de ahí que creasen los Core Ultra X9, potenciados por una GPU Arc B390 (12 Xe-Cores y hasta 122 TOPS). Con esta diapositiva apuntaron a un gaming en 1080p con ajustes Altos de más de 100 FPS en varios juegos y sin reescalados.
Yo mismo expliqué los planes de Intel bLLC, una de las alternativas directas a 3D V-Cache en lo que a interconexiones se refiere. Es una tecnología de apilado de caché L3 de forma vertical que llegaría con Nova Lake, los Intel Core Ultra 400 de escritorio.
Intel usaría un paquete 2.5D, alcanzando 144 MB de caché totales (al igual que AMD), además de haber la posibilidad de tener un bLLC Dual para llegar a más de 200 MB de caché totales. Vamos, lo mismo que ha hecho AMD con sus X3D, como el Ryzen 9 9950X3D2.
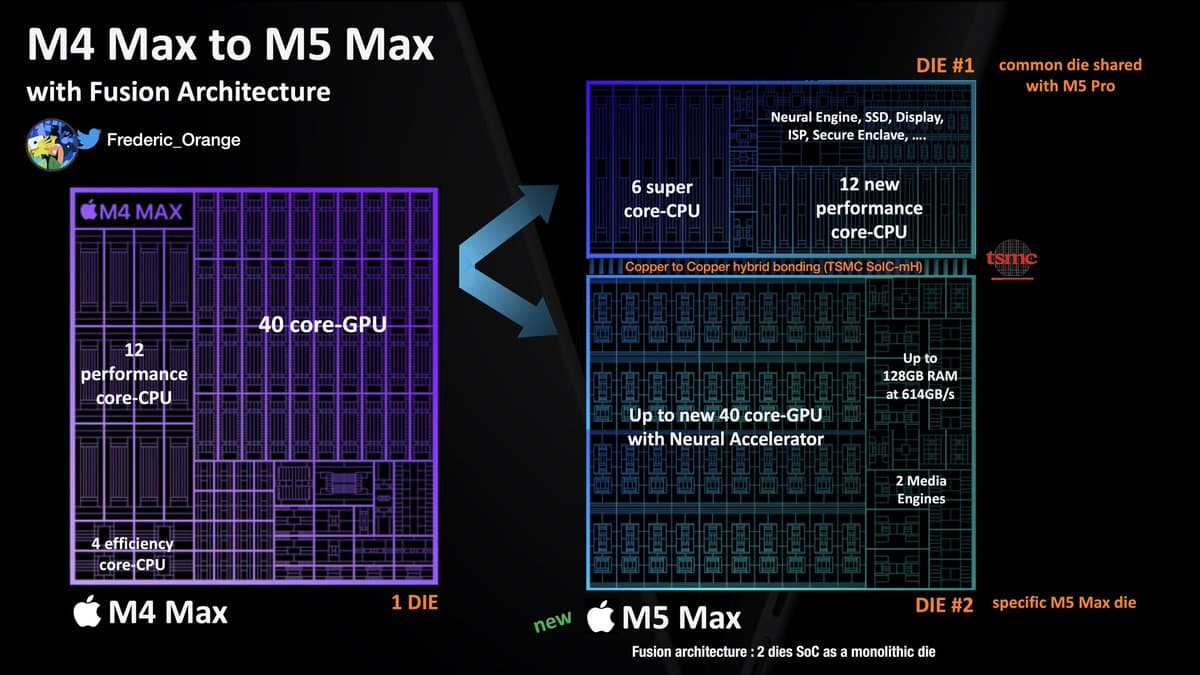
Apple decidió unir 2 chips mediante un puente de silicio pasivo para dotar a sus M5 Ultra de más ancho de banda (+2.5 TB/s). Así nació Fusion Architecture, que no llega a ser 3D, sino 2.5D.
Con el M4 Max teníamos un die con 40 núcleos en la GPU y hasta 16 cores en la CPU. Para avanzar en rendimiento, hay que meter más músculo al chip, y Apple vio que hacerlo en un solo die dificultaba todo: más mm², más calor y ciertos problemas de escalabilidad.
Como dijo Julio César: divide y vencerás, por lo que Fusion Architecture se trata de una fusión de 2 dies SoC en un die monolítico. En un die tenemos la CPU compuesta por 6 +12 núcleos, el neural engine y demás, mientras que en el otro tenemos toda la GPU con sus 40 núcleos con su memoria RAM unificada y 2 motores multimedia.
Gracias a TSMC y su tecnología SoIC-mH unen esos 2 dies en uno con Hybrid Bonding, la misma tecnología que AMD 3D V-Cache. Sin embargo, aquí la interconexión es horizontal, no vertical, por lo que denominarla «3D» es incorrecto, pero está bien el ejemplo, ¿no?
El resultado es que los M5 Ultra y Max tienen toda la RAM accesible por la GPU porque está en el mismo die, aumentando claramente su rendimiento porque ellos usan RAM unificada. Además, consiguen mover más datos consumiendo menos energía, poca broma.
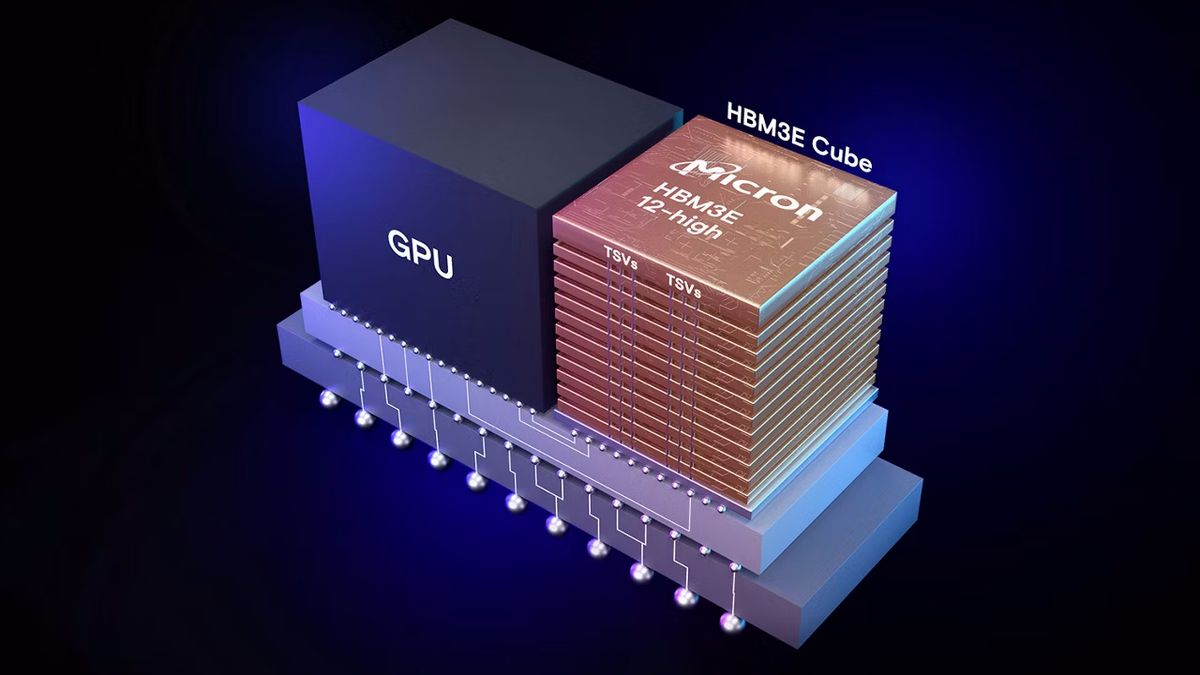
Al principio del post he comentado que SK hynix y AMD fueron los precursores de HBM como tecnología de memoria de vídeo con alto ancho de banda. Para conseguirlo apilaron capas de DRAM verticalmente porque la superficie del chip era limitada, por lo que hay un efecto Tokyo: lo óptimo es construir hacia arriba.
Para interconectar las capas de DRAM se usaba el TSV (Through-Silicon Vias), conocido como interposer, que eran unas vías microscópicas que atravesaban el silicio de cada capa. En la base del die tenemos al chip lógico, que es un controlador encargado de gestionar todos los datos y su transmisión entre las capas; vamos, un cerebro que ordene todo.
Resultado: GPUs con más de 50 GB de memoria VRAM. A nivel usuario esto no otorga utilidad, pero a los datacenters y servidores… es un avance tremendo por la cantidad de clientes que acceden a esas GPUs. Y ya no hablo de número de clientes, sino la capacidad que tiene cada GPU para aprender LLM o ejecutar una tarea compleja.
Con HBM4 tenemos un bus de memoria de 2048-bit, anchos de banda de hasta 3.2 TB/s y configuraciones de VRAM que pueden llegar a más de 500 GB. Sí, NVIDIA Vera Rubin Superchip tiene un total de 576 GB HBM4, siendo un sistema compuesto por una CPU y 2 GPUs. AMD supera los 400 GB de HBM4 en sus Instinct MI455X o MI430X.
Teniendo en cuenta que AMD y SK fueron los pioneros en interconexiones 3D, los demás han ido a remolque de estos 2 gigantes. No obstante, Intel planea un contraataque directo con bLLC, Apple tiene un Fusion Architecture que nos recuerda al diseño chiplet de AMD y la memoria HBM es fabricada por SK, Samsung y Micron.
La alternativa clara a 3D V-Cache es Intel bLLC, pero AMD no debería limitar su atención a los de Arizona porque Apple ya juega con interconexiones 3D. Asimismo, hay proyectos interesantes en el camino: Intel PovwerVia, Co-Packaged Optics (Ayar Labs e Intel), XTCO (IMEC + TSMC), Saint-D (Samsung) y seguro que se me escapa alguno que otro.
A nivel usuario, tardaremos en ver una competencia directa a 3D V-Cache, centrándose la gran mayoría en usos profesionales. Está claro que el futuro de los chips pasa por la integración heterogénea y el 3D.
Te recomendamos los mejores procesadores del mercado
El mercado de las consolas portátiles de gama alta ha sumado un nuevo competidor. La…
Chen Li-bai, el presidente de ADATA, uno de los principales fabricantes de memoria a nivel…
Aunque la inteligencia artificial ofrece grandes ventajas creativas, también plantea un riesgo, que son la…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}