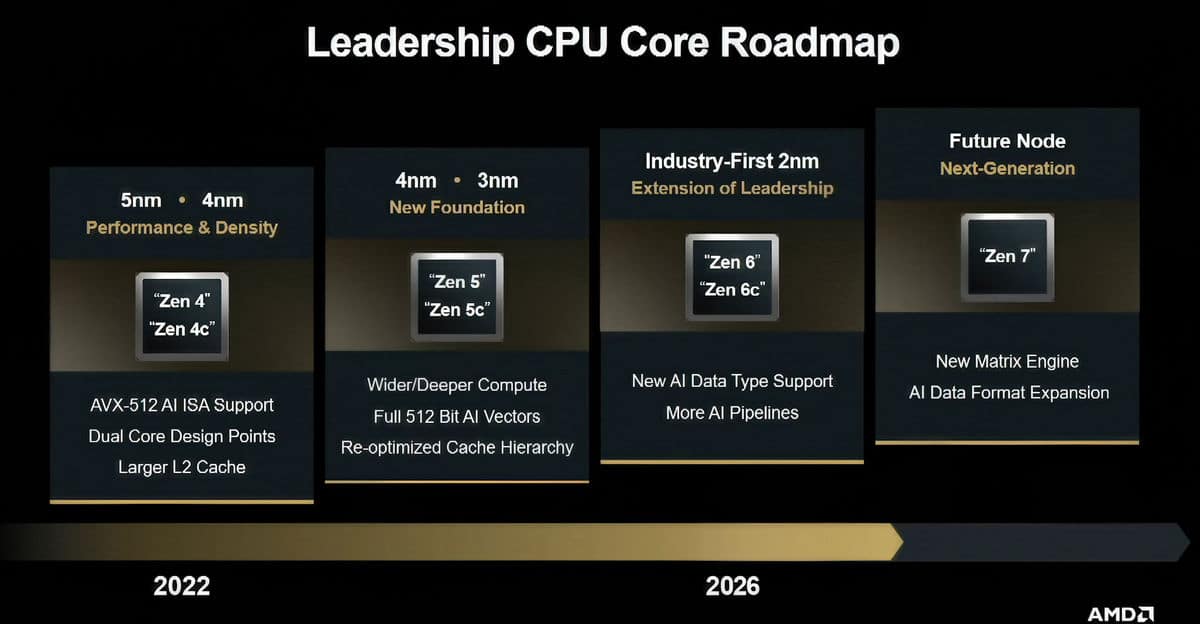
La microarquitectura Zen 6 promete mejoras en eficiencia, IPC y capacidades de IA frente a Zen 5, marcando el siguiente salto evolutivo en procesadores AMD. Conocer las novedades y mejoras es clave para predecir qué es lo que nos espera para esta nueva generación, y si podrá ser un buen rival para lo que prepara Intel.
Índice de contenidos
| Característica | Zen 5 | Zen 6 |
| Foco del diseño | Evolución basada en Zen 4. ~10–15% vs Zen 4 | Rediseño mucho más profundo orientado a mejorar el throughput y paralelismo. Rumores ~10–15% vs Zen 5 |
| Codename | Nirvana | Morpheus |
| Nodo de fabricación CCD | TSMC N4 / N4P (4 nm) | TSMC N2 (2 nm) |
| Diseño chiplet | CCD + IOD | CCD + IOD mejorado, manteniendo filosofía modular |
| Núcleos por CCD | 8 núcleos | 12 núcleos |
| Organización CCX | 1 CCX unificado de 8 núcleos | Probable CCX unificado de 12 núcleos |
| Caché L3 por CCD | 32 MB | 48 MB |
| Ratio L3 por núcleo | 4 MB por núcleo | 4 MB por núcleo (se mantiene) |
| Tamaño aproximado CCD | ~71 mm² | ~76 mm² |
| Frontend | Más ancho que Zen 4, mejoras en predictor y fetch | Diseño todavía más ancho y agresivo |
| Dispatch | Menor que 8-wide | 8-wide dispatch |
| SMT | SMT2 | SMT2 con reparto dinámico de slots de dispatch |
| AVX-512 | Soporte completo introducido en Zen 5 | AVX-512 ampliado y más orientado a IA/vectorización |
| Capacidades IA | Mejoras moderadas | Nuevos tipos de datos IA y más pipelines IA |
| Nuevas extensiones ISA | AVX-512, mejoras FP | AVX512_FP16, AVX_VNNI_INT8, AVX_IFMA, AVX512_BMM, etc. |
| Floating Point / Vector | Mejorado respecto a Zen 4 | Mucho más fuerte en vectorización y throughput FP |
| Scheduler | Diseño clásico unificado | Posible división en múltiples schedulers especializados para tipos de instrucciones distintos |
| Interconexión interna | Infinity Fabric (IF) refinado | D2D “Sea of Wires” más ancho y rápido |
| Escalabilidad escritorio | Hasta 16 núcleos | Hasta 24 núcleos |
| Escalabilidad servidor/HPC | EPYC Turin hasta 192 Zen 5c | EPYC Venice hasta 256 núcleos |
| Frecuencias objetivo | ~5.7–6 GHz | Rumores de hasta ~7 GHz |
| Compatibilidad socket | AM5 | AM5 (mantiene compatibilidad) |
| 3D V-Cache | Sí | Continuidad prevista de X3D |
| Enfoque competitivo | Intel Arrow Lake / Lunar Lake | Intel Nova Lake y Xeon next-gen |
Te recomiendo leer sobre los mejores procesadores de la actualidad
Zen 6 mantiene la arquitectura modular en chiplets de Zen 5. Cada procesador sigue compuesto por uno o varios CCD (CPU chiplet) más un chiplet I/O con controlador de memoria y E/S. Lo nuevo es el diseño del CCD, ya que en Zen 5 cada CCD tenía 8 núcleos (16 hilos), 8 MB de caché L2 y 32 MB de L3, fabricados en 4 nm, mientras que en Zen 6 cada CCD acomoda hasta 12 núcleos (24 hilos) con 12 MB de L2 y 48 MB de L3 (TSMC 2 nm). Esto supone un incremento del 50 % en núcleos e igual proporción en L2/L3 por CCD.
Así, un procesador con dos CCD puede llegar a 24C/48T, 24 MB L2 y 96 MB L3 totales, por ejemplo, el hipotético Ryzen 9 10950X tendría 24C/48T, 24 MB L2 y 96 MB L3, frente a 16C/32T, 16 MB L2 y 64 MB L3 de su homólogo Zen 5 (Ryzen 9 9950X).
Zen 6 continúa usando el socket AM5, igual que Zen 5, facilitando la compatibilidad con placas base existentes tras una actualización de UEFI.
El aumento de núcleos y caches va acompañado de mejoras en el IPC: las filtraciones indican +10–15 % de IPC sobre Zen 5, junto con frecuencias pico de unos 6,0–6,2 GHz en cargas ligeras. Para contexto, Zen 5 alcanzó ~5,7 GHz de pico, por lo que Zen 6 sumaría ~300–500 MHz extra en cargas de uno o dos hilos.
Además, Zen 6 mejora el controlador de memoria o MMU integrada, ya que soportará DDR5 a ~8000 MT/s de forma nativa (vs ~5600 MT/s garantizados en Zen 5). Esto triplica el ancho de banda teórico de memoria, aprovechando mejor los núcleos adicionales.
Te puede interesar conocer más sobre cómo montar tu propio PC
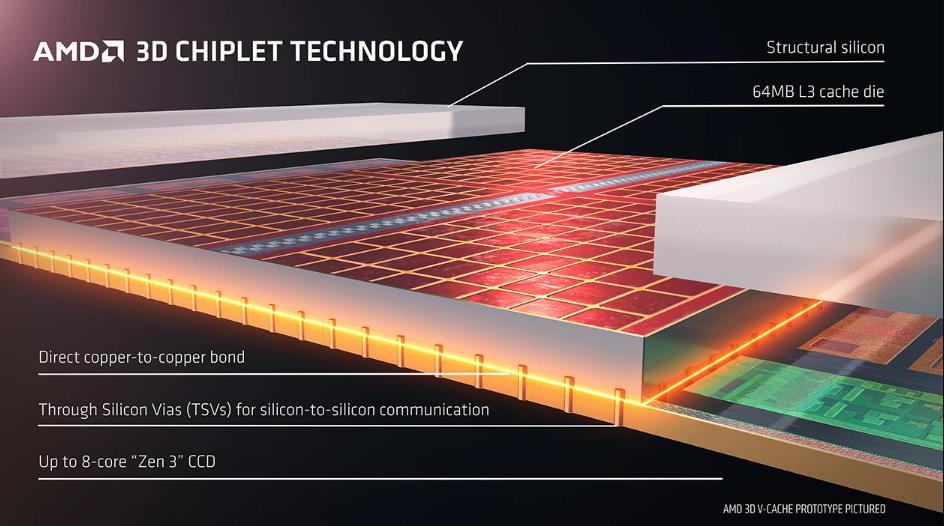
Zen 5 ya introdujo CPUs X3D con caché L3 apilada en 3D de 64 MB (2×32 MB por CCD). Zen 6 sigue esta idea con una 2.ª gen. de 3D V-Cache. Como la capacidad L3 por CCD crece a 48 MB, el chiplet apilado ahora ofrecería 96 MB de L3 en 3D por CCD. Esto significa un total de ~192 MB en un procesador de dos CCD con 3D (vs 128 MB en Zen 5 X3D). A mayor caché L3, la escalada del rendimiento en juegos y aplicaciones dependientes de caché L3 será más pronunciada.
No sabemos si habrá un Ryzen 10000X3D2 aún…
Las filtraciones de AMD indican que el núcleo Zen 6 tiene un front-end muy ancho. Por ejemplo, un motor de despacho de 8 vías con SMT (2 hilos por núcleo). Esto es superior a Zen 5 (which used 6 ALUs) y permite procesar más instrucciones por ciclo. AMD ha preparado contadores internos dedicados para cuantificar espacios de despacho vacíos y conflictos de SMT, evidenciando el enfoque en ancha emisión y multihilo.
En el plano de las unidades aritmético-lógicas o de ejecución, Zen 6 expande las capacidades. Con soporte nativo AVX-512 de 512 bits para todos los formatos (doble precisión FP64, simple FP32, medio FP16 y BF16), incluyendo operaciones FMA/MAC y extensiones VNNI (int8), AES y SHA. A diferencia de Zen 5, que ya tenía AVX-512 (con pipelines ampliadas a 512-bit en desktop), Zen 6 maneja internamente estos vectores de modo que puede sostener un throughput de 512 bits/ciclo suficiente para saturar los contadores tradicionales.
Según Tom’s Hardware, Zen 6 puede procesar “tanto trabajo vectorial por ciclo que supera las técnicas convencionales de medición”.
El procesador también mejora la estructura de programación de enteros. Se menciona la existencia de seis dominios separados de scheduler entero, lo que significa que los recursos aritméticos se dividen en regiones independientes para reducir latencias y congestión interna. En Zen 5 ya había 6 ALUs, y Zen 6 mantiene (o distribuye) esa capacidad con una lógica refinada. En conjunto, estas mejoras en la lógica interna aumentan el IPC neto frente a Zen 5, además de permitir mayor paralelismo.
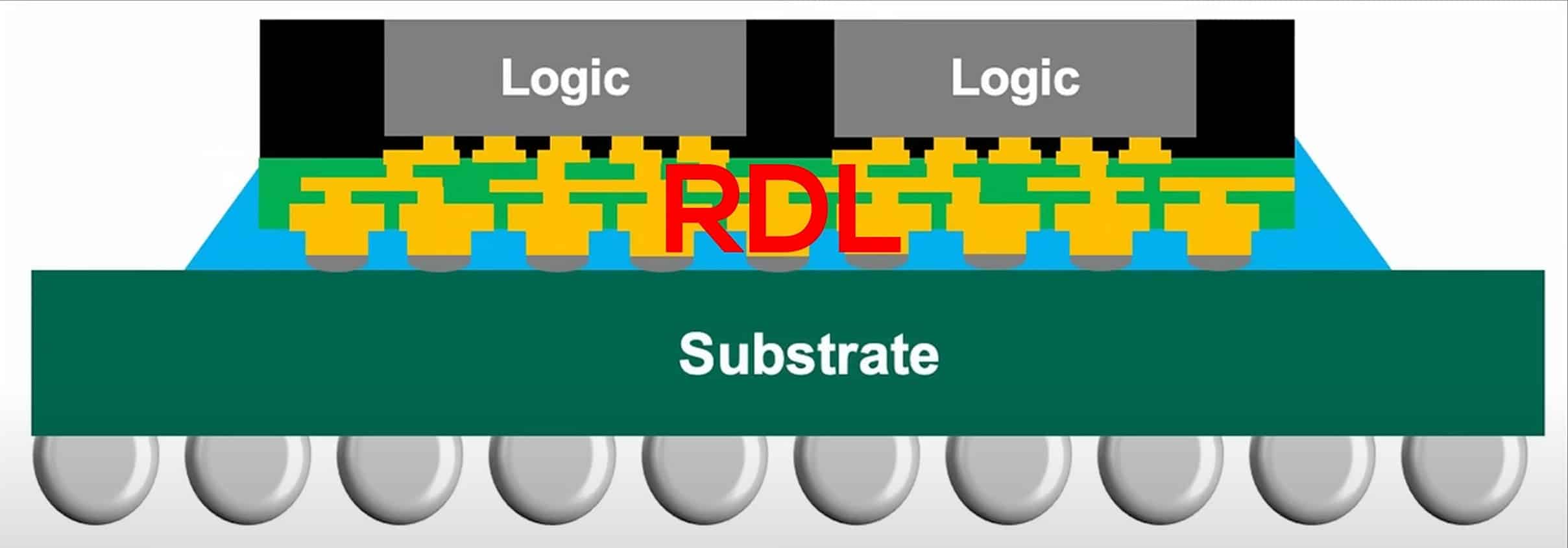
Uno de los cambios más revolucionarios de Zen 6 está en el enlace die-a-die (CCDs↔IOD). Hasta Zen 5 se usaban canales SERDES de alta velocidad, pero Zen 6 adopta un esquema tipo “mar de cables” (miles de trazas paralelas cortas en capas RDL del sustrato). Esta arquitectura ya se vio en los APUs Ryzen AI (Strix Halo). El resultado es una gran reducción de latencia y consumo en la comunicación chiplet. Se estima que mover datos entre CCD e IOD consume ~90 % menos energía.
Además, el ancho de banda crece drásticamente al sumar trazas paralelas, liberando a cada CCD para acceder a más memoria sin cuellos de botella. En la práctica, Zen 6 tendrá un interconector más ancho y rápido que en generaciones previas, con latencias sensiblemente inferiores. Esto beneficiará especialmente cargas multi-chiplet (EPYC multinúcleo) y aplicaciones sensibles a la memoria.
Zen 6 incorpora varias instrucciones nuevas en conjunto con Intel (grupo x86 Ecosystem). Destacan:
Zen 6 amplía y refina cada bloque funcional de Zen 5, con muchos más cambios esperados que en Zen 5 respecto a Zen 4. Es decir, se puede hablar de que es una «revolución», no una simple evolución. Además, lo positivo es que conserva el socket AM5, pero con las mejoras introducidas se espera que sus capacidades de ejecución en aplicaciones de IA, cálculo y gaming sean muy superiores.
¡Deja tus comentarios!
Valve ha publicado una actualización dedicada al estado de su consola de sobremesa, la Steam…
El mini PC Khadas Mind Pro, impulsado por el procesador Intel Core Ultra X7 358H,…
KIOXIA ha anunciado la serie NX1, su primera familia de unidades SSD preparada para funcionar…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}