Los modelos LLM open source permiten ejecutar modelos avanzados directamente en tu PC, sin depender de la nube y con total control sobre privacidad y personalización. Hoy existen opciones potentes y accesibles para cualquier usuario doméstico, y con diferentes tamaños para adaptarse a tu hardware.
Índice de contenidos
Te puede interesar conocer cuáles son las mejores tarjetas gráficas para IA
Elegir un LLM local no es fácil, especialmente para algunos que son nuevos en este mundillo de la IA. Para saber cómo buscar el adecuado, es importante conocer ciertos parámetros que debes mirar de un modelo antes de elegir:
El primer parámetro crítico es el tamaño del modelo, medido en número de parámetros. Lo identificarás fácil porque es un número seguido de una letra M (millones) o B (billones americanos, es decir, miles de millones para los europeos). Mientras mayor sea, más «inteligente» o capaz será el modelo. Por ejemplo, podemos ver modelos de 7B, 13B y 70B, por supuesto, el 70B sería el más complejo, pero cuidado, ya que no siempre te interesa uno tan grande, ya que mientras más capacidad de razonamiento y comprensión, más capacidad de memoria RAM y VRAM necesitarás para su ejecución. Además, los modelos más pequeños no solo requieren un hardware más modesto, sino que son también más rápidos para tareas sencillas.
Si cuentas con una CPU y GPU modesta o integrada, y con poca RAM, mejor elige modelos pequeños como 7B. Si tienes un hardware top, con una CPU con NPU de las últimas, y una tarjeta gráfica de alta gama, entonces puedes elegir algo más intermedio. En cambio, para modelos superiores a 70B o 100B, solo existe la opción de usar HPC.
Es un poco complicado dar datos exactos, pero para que te hagas una idea, cada 1B puede requerir en torno a en torno a 1GB de VRAM, y eso habría que multiplicarlo por 2 o 3 para calcular la RAM necesaria, lo cual sería entre 2 y 3GB de RAM en este caso.
Conforme aumenta el tamaño, también necesitarás más capacidad de almacenamiento para descargar el modelo completo, desde unos cientos de Megas, hasta decenas o centenares de GB en tu disco duro…
La arquitectura define cómo procesa la información el modelo. En este caso, hay que analizar el tipo, si es decoder-only, encoder-decoder, o híbrido. También la eficiencia interna, capacidad de contexto o longitud máxima de ventana y la optimización para razonamiento que tenga. Esto puede ser complejo para principiantes y no tan principiantes, puesto que implicaría analizar el modelo más profundamente. Pero dependerá del tipo de tareas que quieras ejecutar localmente con el modelo LLM.
Las arquitecturas más densas consumen mayor cantidad de recursos de hardware, es decir, necesitarán más VRAM, ancho de banda, y TFLOPS. Como regla, si tienes un hardware más modesto, elige un modelo decoder-only, y si tienes hardware superior encoder-decoder o híbrido.
La ventana de contexto determina cuántos tokens puede procesar el modelo simultáneamente. Cuanto mayor sea la ventana, mejor para el análisis de documentos largos o para analizar muchos datos a la vez. Por supuesto, mientras más grande, más consumo de memoria tendrá, aunque existen algunos modelos que usan compresión de contexto o atención selectiva para reducir las necesidades de memoria.
Se mide en tokens. La memoria caché necesaria aumenta linealmente con el aumento de tokens por ventana, mientras que las necesidades de VRAM aumentan de forma longitudinal del contexto. Por lo general, por cada duplicación de ventana se puede aumentar el uso de entre 30-60% el uso de VRAM. No obstante, si te parece complejo, encontrarás los requisitos necesarios de los modelos más populares…
La cuantización permite ejecutar modelos grandes en hardware limitado reduciendo la precisión numérica. Se mide en bits por peso (4-bit, 5-bit, 8-bit,…), y tiene un impacto directo en la forma de procesar los datos, algunas pueden degradar más el rendimiento que otras, y de ello dependerá también la compatibilidad del hardware (CPU, NPU, GPU,…), ya que no todas soportan en su ISA trabajar con estos tamaños de datos. Además, tenemos formatos soportados diferentes, como GGUF, ONNX, Safetensors, etc.
En este caso, mientras mayor sea la cuantización, menos tamaño de VRAM necesitará el modelo y también menos memoria RAM necesita. Por ejemplo, 4-bit puede reducir el uso de VRAM hasta en un 75% en algunos casos respecto a 16-bit, y un 8-bit puede reducirlo en torno al 50%. Eso sí, mientras más pequeño, se aumentará las necesidades de tráfico de datos, lo que implica tener un buen ancho de banda…
Vigila también la compatibilidad con tu hardware, no solo según los recursos disponibles, también la compatibilidad con aceleradores CUDA, ROCm, DirectML, etc., ya que no todos son compatibles con todos…
El rendimiento no depende solo del tamaño del modelo, sino también de los tokens por segundo capaces de procesar, la optimización del motor de inferencia que se use, batching y paralelización del modelo, y eficiencia de su arquitectura. Por lo general, un modelo más pequeño bien optimizado podría incluso superar a un modelo grande y mal implementado.
Como regla para la elección, con una GPU que pueda tener más de 10 TFLOPS y más de 400 GB/s de ancho de banda, la inferencia será fluida. Por debajo de eso, la inferencia es lenta…
Para evaluar la calidad, se utilizan benchmarks estandarizados, como se usan para el hardware. Estos benchmarks especializados para comparar modelos LLM se basan en medir el razonamiento lógico, comprensión de lenguaje, matemáticas, codificación, y conocimiento general. Por ejemplo, se pueden encontrar puntuaciones normalizadas tipo 0-100, en tanto por ciento %, F1, BLEU, etc. Puedes encontrar resultados de benchmarks en la red si quieres comparar modelos…
Si planeas personalizar el modelo, debes evaluar:
Un modelo flexible permite adaptarse a dominios específicos sin reentrenarlo desde cero.
Si vas a usar el modelo para uso comercial, ten en cuenta que aunque la licencia sea de código abierto, algunas pueden se restrictivas para este tipo de uso, o limitar la modificación, etc.
Un modelo con una comunidad activa ofrece:
Esto influye directamente en la facilidad de uso a largo plazo.
Si quieres saber más sobre la IA, aquí tienes más contenido…
Dicho esto, ahora que ya deberías tener las herramientas necesarias para poder elegir el correcto en tu caso, te lo vamos a poner aún más fácil mostrándote algunos de los mejores con los que puedes probar:
Existen también modelos híbridos, que pueden combinar dos de estos…
No olvides que para facilitarte el uso de estos modelos ya cuentas con gran cantidad de aplicaciones en las que usar varios modelos fácilmente en tu sistema, como puede ser Ollama, LM Studio, vLLM, etc., muchas de ellas disponibles para Windows, Linux, y macOS.
Como es comprensible, ejecutar la IA en local tiene sus ventajas y desventajas. Y aunque los diseñadores de chips cada vez integran unidades aceleradoras como la NPUs más y más potentes para el uso de la IA en local, lo cierto es que se sigue dependiendo demasiado de los servicios en la nube.
Y recuerda, para optimizar el rendimiento y ahorrar recursos cuando ejecutas la IA en local, existen algunos consejos:
Si tienes sugerencias, no olvides comentar…
Pulsar y Noctua han presentado el Feinmann F01 Noctua Edition, un ratón gaming con ventilación…
La preservación de los juegos ha sumado un nuevo logro. Dolphin, el emulador de Nintendo…
Acer se prepara para ingresar de lleno al competitivo mercado de las consolas portátiles de…
{kind=link}
{kind=link}
{kind=link}
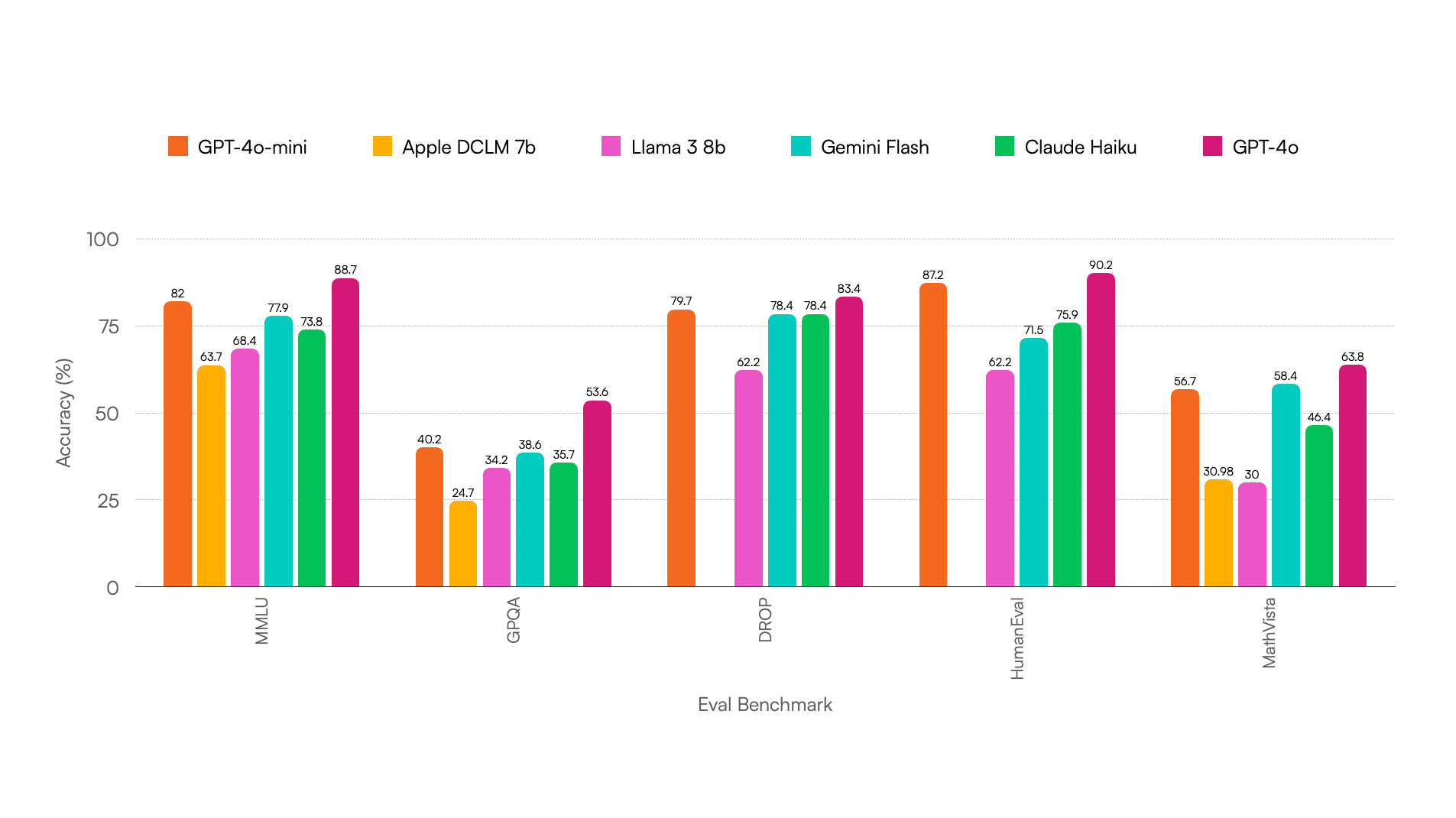{kind=link}
{kind=link}